대세는 쿠버네티스 [초급~ 중급] - 중급편
섹션 0. 강의소개
[강의] https://www.inflearn.com/course/쿠버네티스-기초/dashboard
대세는 쿠버네티스 [초급~중급] - 인프런 | 강의
쿠버네티스는 앞으로 어플리케이션 배포/운영에 주류가 될 기술 입니다. 이 강좌를 통해 여러분도 대세에 쉽게 편승할 수 있게 됩니다., [사진] 쿠버네티스는 디플로이 자동화, 스케일링, 컨테이
www.inflearn.com
섹션 1. [중급편] pod
1. Pod - Lifecycle
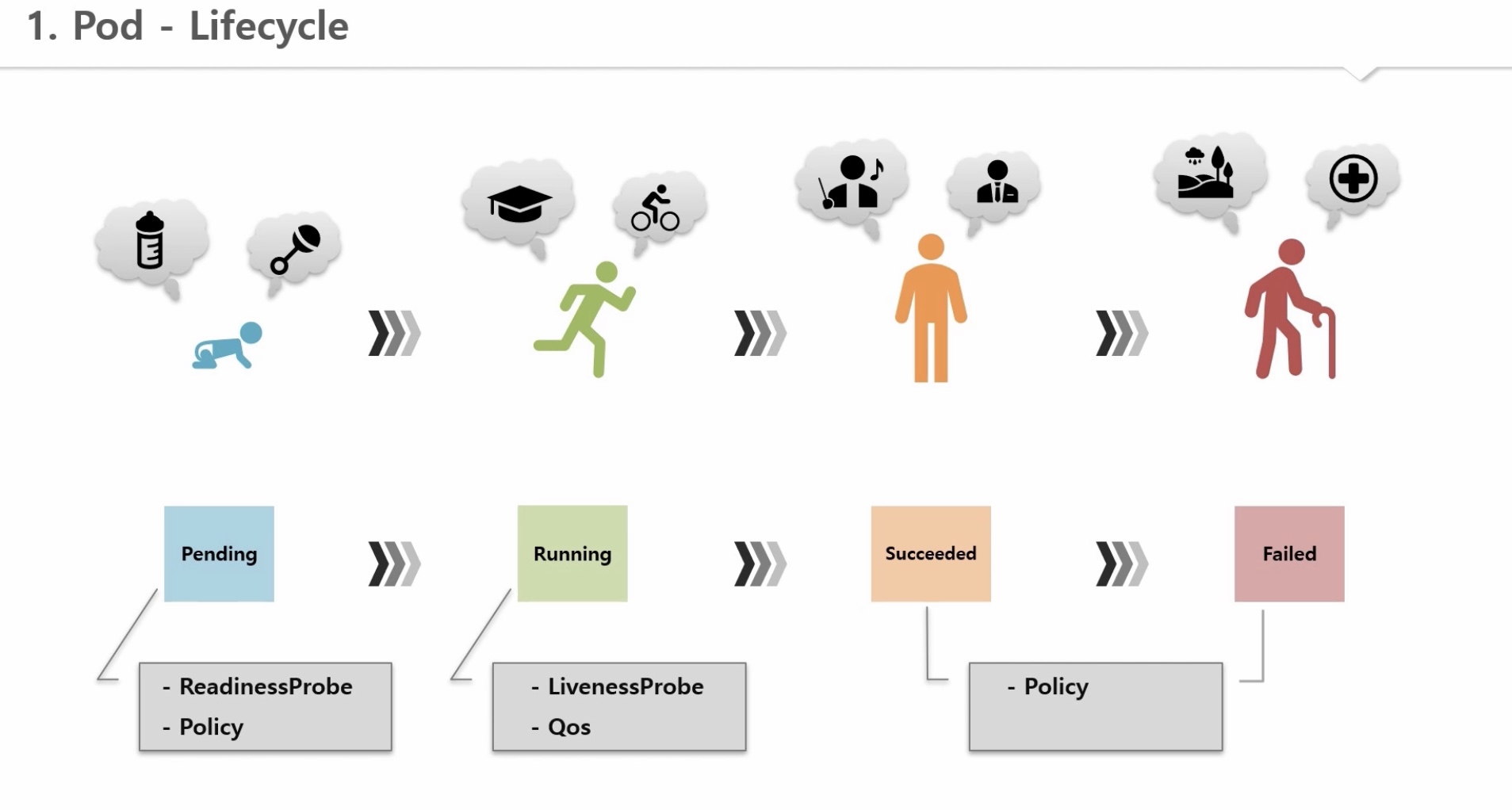
1) 파드 status
- Phase: 파드의 메인 상태
=> Pending, Running, Succeeded, Faild, Unknown
- Conditions: 파드 세부 상태 (false인 경우, reason 으로 원인 파악)
=> Initialized, ContainerReady, PodScheduled, Ready
=> Reason: ContainersNotReady, PodCompleted
2) 컨테이너 status
- State: 컨테이너 상태
=> Waiting, Running, Terminated (reason으로 상세 내용 확인)
=> Reason: ContainerCreating, CrashLoopBackOff, Error, Completed

* 파드의 phase 별 동작
1) Pending: 파드 및 컨테이너 생성 - Waiting/ContainerCreating
- Initialized: iniContainer를 통한 초기 설정이 없거나 정상 완료되면 true / 실패하면 false

- PodScheduled: 노드 스케쥴링 또는 개별 파드 스케쥴링 완료 시 true
2) Running
a. 컨테이너 기동 완료 - 컨테이너 문제 발생 경우: Waiting/CrashLoopBackOff
- ContainerReady: False
- Ready: False
* 파드가 Running 중이라도 내부 컨테이너에 문제가 있을 수 있음
b. 컨테이너 정상 기동 완료 - Running
- ContainerReady: True
- Ready: True
3) Failed / Succeeded(job 이나 cronjob 작업 완료 시)
a. Succeeded: 컨테이너 모두 정상 완료 시 (Terminated/Completed)
- ContainerReady: False
- Ready: False
b. Failed: 컨테이너 중 하나 이상 문제 발생 시 (Terminated/Error)
- ContainerReady: False
- Ready: False
4) Failed / Unknown
- Pending 또는 Running 상태에서 문제가 발생하여 파드 상태가 변경될 수 있음

1. Pod - Readinessprobe, Livenessprobe
1) Readinessprobe
- 두개 노드로 서비스하다가 한 노드에 문제가 발생한 경우, 해당 노드가 재기동 되는 동안 기존 노드로 100%의 트래픽이 몰리고 해당 노드가 재기동 되자마자 다시 분산한다. 하지만 노드 재기동 후 어플이 재기동 되므로 이 시간동안 에러가 발생하게 되는데 이를 방지해줌(앱 구동 순간의 트래픽 실패 방지)
2) Livenessprobe
- 유사한 상황에서 노드는 정상인데 어플에 문제가 생기는 경우, 파드를 재실행시켜 지속적인 트래픽 실패를 예방

* Readinessprobe, Livenessprobe 설정내용(동일)
A. 아래 셋 중 하나는 필수
1) httpGet: port, host, path, httpheader, schema 체크
2) Exec: 특정 명령어를 날려 그에 따른 결과 확인 가능
cat /tmp/ready.txt
3) tcpSocket: port, host 체크를 통해 설정 성공 여부 확인
B. optional (괄호 안은 기본값)
1) initialDelaySeconds: 최초 probe 하기 전 delay 시간 (0초)
2) periodSeconds: probe 체크 시간 간격 (10초)
3) timeoutSeconds: 지정된 시간까지 결과가 와야함 (1초)
4) successThreshold: 성공으로 인정하는 횟수 (1회)
5) failureThreshold: 실패로 인정하는 횟수 (3회)

[case1] ReadinessProbe
1) 최초: pod, container는 running 상태이지만, ContainerReady, Ready 값은 false
=> endpoint에서 파드를 NotReadyAddr 상태로 간주하고 서비스에 연결하지 않음
2) k8s가 앱 기동 상태를 체크하다가 컨테이너 상태가 running이 되면 5초간 기다린 후 ready.txt 파일 존재 여부 체크
3) 파일이 없으면 10초 후 다시 체크
4) 3번의 시도 이내에 파일을 찾으면 성공 결과를 받음 (해당 파일이 컨테이너의 볼륨과 연결되어 있음)
5) 성공 결과를 받으면 ContainerReady, Ready 값이 true로 바뀜
=> endpoint도 파드를 Addresses 상태로 인지하고 서비스와 연결
[case2] LivenessProbe
1) k8s가 5초간 기다린 후 httpGet로 해당 패스(/health)를 앱 기동 상태를 체크해보고 200 status ok를 받음
2) 성공하면 10초를 기다린 후 httpGet로 해당 패스(/health) 다시 체크
3) 위를 반복하다가 어느 순간 500 status error를 받음
4) 500 status error를 연속으로 3회 받으면 k8s가 해당 파드를 리스타트 시킴

1. Pod - Readinessprobe, Livenessprobe 실습
[참고] https://kubetm.github.io/k8s/06-intermediate-pod/probe/
Readinessprobe, Livenessprobe
Readinessprobe, Livenessprobe
kubetm.github.io
1) ReadinessProbe
- 서비스 ip로 1초마다 트래픽 날리기 => 기존 파드만 연결됨
while true; do date && curl 10.97.190.80:8080/hostname; sleep 1; done
- 파드의 이벤트 상황 체크 (진행중인 이벤트 성공/실패 확인 가능) => ReadinessProbe 반복 시도중
kubectl get events -w | grep pod-readiness-exec1
- ReadinessProbe 상태 체크 => ContainerReady, Ready 값 = false
kubectl describe pod pod-readiness-exec1 | grep -A5 Conditions
- endpoint 체크 => Addresses: 기존 파드 ip / NotReadyAddr = 신규 파드 ip
kubectl describe endpoints svc-readiness
- 파일 생성 => 위 커맨드로 체크 시, 모두 정상으로 바뀜
cd /tmp/readiness/
touch ready.txt
2) LivenessProve
- 서비스 ip로 1초마다 트래픽 날리기 => 두 파드에 모두 연결됨
while true; do date && curl 10.103.160.58:8080/health; sleep 1; done
- 해당 파드의 이벤트 상황 체크 => 컨테이너가 잘 만들어져서 시작됨
watch "kubectl describe pod pod-liveness-httpget1 | grep -A10 Events"
- 파드의 클러스터 ip로 500 status 에러 생성 => 3회 확인 후 파드 재시작됨
curl 20.109.131.43:8080/status500
* Object들의 모든 Event 정보를 지속적으로 조회해서 | 그중에 pod-readiness-exec1라는 단어와 매칭되는 내용만 출력
kubectl get events -w | grep pod-readiness-exec1
* pod-readiness-exec1이름의 Pod 상세 내용중에 | Events와 매칭되는 단어에서 20번째 줄까지 지속적으로 출력
watch "kubectl describe pod pod-readiness-exec1 | grep -A20 Events"
* HTTP status: 200~400까지는 성공, 그 외는 실패
1. Pod - QoS classes (Guaranteed > Burstable > BestEffort)
* 노드 내 자원이 오버되어야 하는 경우, 파드 지원 우선 순위 (Quality Of Service)
1) Guaranteed
- 모든 컨테이너에 request와 Limit이 설정되어야 함
- 각 request와 Limit에는 memory와 cpu가 모두 설정되어야 함
- 각 컨테이너 내 memory와 cpu의 request와 Limit의 값이 같음
2) Burstable
- 그 외 request와 Limit를 부분적으로 설정하는 경우
- Burstable 내 파드 우선순위 결정: OOM(Out Of Memory) Score 에 따름
=> request 메모리 대비 실제 사용 메모리 비율이 높은 파드를 우선 제거

3) BestEffort
- 모든 컨테이너에 request와 Limit 미설정

1. Pod - Node Scheduling

[노드 선택]
1) NodeName: 원하는 노드 이름을 지정해주는 방법
- 노드는 재생성 시 이름이 바뀌기 때문에 잘 사용하지 않음
2) NodeSelector: 원하는 라벨이 붙은 노드로 할당(동일한 라벨을 가진 노드가 여러개면 스케쥴러가 판단)
- 키-밸류가 모두 일치하는 경우만 가능하고, 일치하는 노드가 없으면 파드는 할당되지 못함(에러 발생)
3) NodeAffinity: 동일한 키를 가진 노드로 할당(동일한 키를 가진 노드가 여러개면 스케쥴러가 판단)
- 일치하는 노드가 없어도 스케쥴러가 판단하여 할당(옵션)
- MatchExpressions: ReplicaSet의 Selector와 유사한 기능으로, 여러 조합(operator)의 키-밸류 조건으로 할당 가능
- Required vs Preferred
a. Required: 반드시 해당 조건에 부합하는 노드로 할당되어야 하는 경우
b. Preferred: 해당 조건에 부합하는 노드로 할당되는 게 좋지만 필수는 아닌 경우
* Preferred Weight: 여러 조건을 넣고 각각에 대해 가중치 부여 가능
=> 스케쥴러가 계산한 노드 점수와 이 가중치를 합산해 할당할 노드 최종 선택

[파드간 집중/분산]
1) Pod Affinity: 여러 파드를 동일한 노드로 할당하는 경우
- 한 파드를 먼저 할당하고, 신규 파드의 Pod Affinity 값을 해당 파드의 라벨로 지정하면 동일 노드로 할당됨
- NodeAffinity는 동일한 조건의 라벨을 가진 노드를 찾지만, Pod Affinity는 파드를 찾고 해당 파드가 있는 노드로 할당
- topologyKey: 지정된 키와 동일한 키를 가진 노드 내에서만 선택 가능 (다르면 할당 불가 => pending 상태)
- Required vs Preferred: Node Affinity와 동일
2) Anti-Affinity: 서로 다른 노드로 할당되어야 하는 경우 (예: master/slave)
- 한 파드를 먼저 할당하고, 신규 파드의 Anti-Affinity 값을 해당 파드의 라벨로 지정하면 다른 노드로 할당됨
- topologyKey, Required vs Preferred: Pod Affinity와 동일
[노드에 할당 제한] Taint / Toleration
- 할당을 제한하고자 하는 노드에 Taint 라벨을 달면, 스케쥴러가 해당 노드로 할당해주지 않고 노드이름을 지정해도 않됨
* effect(Noschedule/PreferNoSchedule/NoExcute): 절대 할당 불가 / 가급적 할당 불가 / 기 존재하던 파드 삭제
* 노드와 파드가 모두 effect = NoExcute 조건으로 생성된 경우에는 삭제되지 않으며,
파드에 tolerationSeconds 조건이 추가로 있는 경우에는 노드에 Taint가 설정되면 해당 시간 이후 삭제됨
- Toleration 키-라벨, effect가 모두 동일한 파드만이 해당 노드에 할당될 수 있음
- 모든 조건이 부합하더라도 해당 파드는 다른 노드에 할당될 수 있으므로 nodeSelector 옵션을 추가해 제한 필요
* NoSchedule 옵션: master 노드에 기본적으로 달려 있어 신규 파드가 할당되지 않음
* NoExcute 옵션: replicaSet에 의해 파드 운영 중일 때 특정 노드에 문제가 발생하면 해당 옵션의 Taint를 달고,
파드가 삭제되면 해당 컨트롤러에 의해 다른 노드에서 재생산됨

1. Pod - Node Scheduling 실습
[참고] https://kubetm.github.io/k8s/06-intermediate-pod/nodescheduling/
Node Scheduling
Node Affinity, Pod Affinity/Anti-Affinity, Toleration/Taint
kubetm.github.io
1) Node Affinity
- 노드에 라벨 달기
kubectl label nodes k8s-node1 kr=az-1
kubectl label nodes k8s-node2 us=az-1
- Required vs Preferred
2) Pod Affinity / Anti-Affinity
- 노드에 라벨 달기
kubectl label nodes k8s-node1 a-team=1
kubectl label nodes k8s-node2 a-team=2
3) Taint / Toleration
- 노드에 라벨 달기
kubectl label nodes k8s-node1 gpu=no1
- 노드에 테인트 달기
kubectl taint nodes k8s-node1 hw=gpu:NoSchedule (생성)
kubectl taint nodes k8s-node1 hw=gpu:NoSchedule- (삭제)
kubectl taint nodes k8s-node2 out-of-disk=True:NoExecute
섹션 2. [중급편] 기본 오브젝트
2. Basic Object - Service
[초급편] 사용자 관점
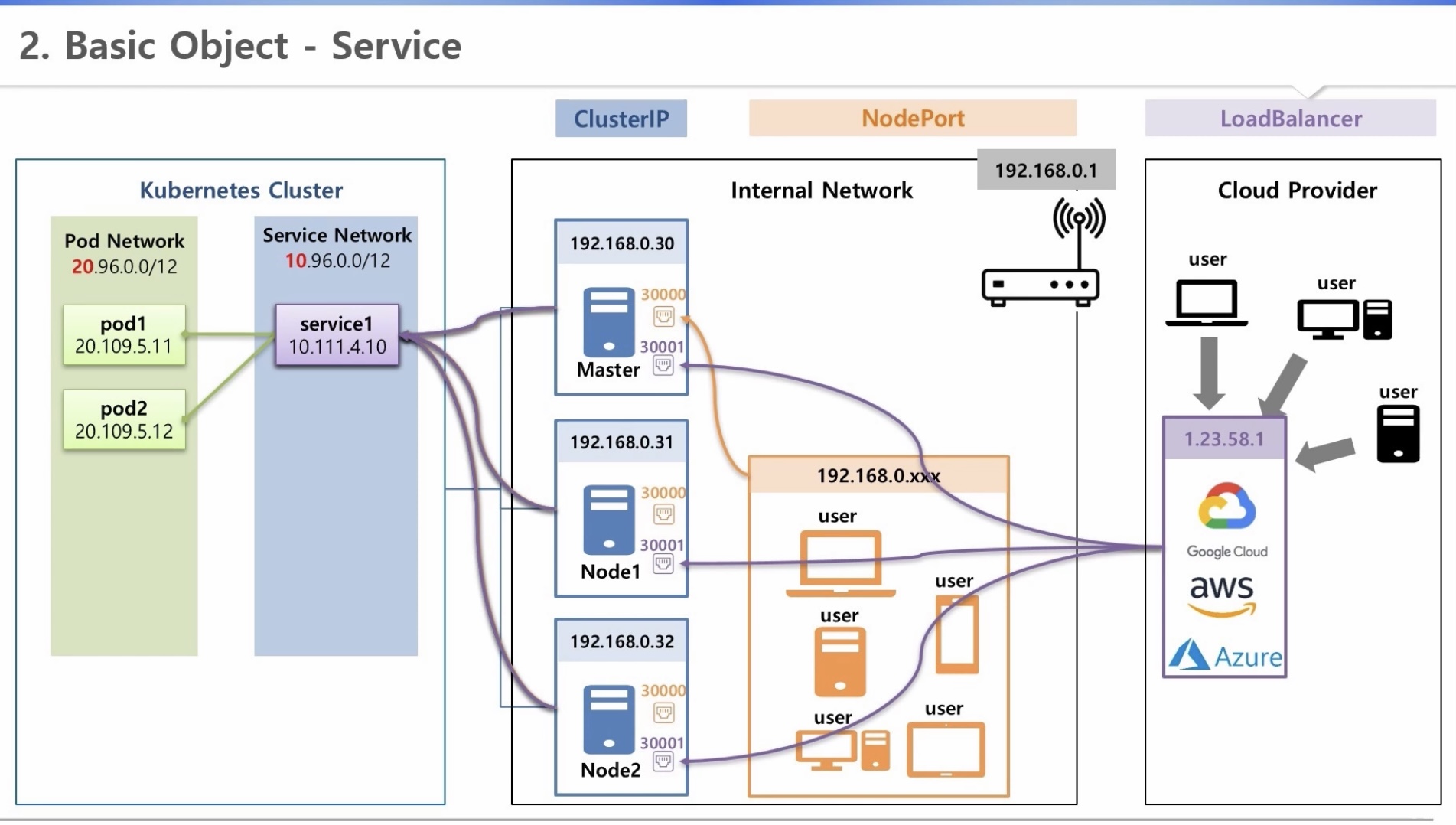
* 파드와 서비스 ip에 각각 다른 대역 설정 가능
* 이미 생성되어 있는 서비스를 통해 접근(확정 ip)
1) ClusterIP
- 쿠버네티스를 구성하고 있는 서버(내부망)에서만 호출 가능
- 내부 관리자만 접근 가능
2) NodePort
- 내부망 ip를 할당받은 외부기기에 접근하고자 할 때, 각 서버에 30000번대 포트가 생성되고 이를 통해 연결
3) LoadBalancer(by CSP)
- 각 서버에 30001번대(?) 노드 포트가 생상되고, 이를 LB와 연결
- 외부망에서 내부 서비스에 접근하고자 하는 경우 사용

[중급편] 파드 관점
* 파드와 서비스가 동시 배포되거나 재생성되는 경우, 각 리소스의 ip를 알 수 없음(비확정 ip)
=> Headless, DNS Server를 통해 해결
* 외부망 접근 주소가 변경되는 경우
=> 파드 변경 없이 서비스의 ExternalName을 통해 외부 연결 변경 가능
1) DNS Server
- 클러스터(Cluster.local)/내부망/외부망 레벨로 존재하며, 서비스의 도메인명과 ip가 저장되어 있음
- 파드가 특정 서버에 대한 도메인명을 질의하면 해당 ip를 알려줌
(클러스터 내부 DNS Server에서 먼저 확인하고, 없으면 상위인 내부망 > 외부망 순서로 확인하여 알려줌)
- 도메인명 생성규칙(FQDN, Fully Qualified Domain Name)
a. 서비스: 서비스명+네임스페이스명+서비스약어(svc)+DNS명
b. 파드: 파드ip+네임스페이스명+파드약어(pod)+DNS명
=> 같은 네임스페이스 안에서 서비스는 도메인명 대신 서비스명으로도 이용 가능

2) Headless
- 두 파드를 연결하고 싶으면 해당 파드에 Headless Service를 연결해야 함
=> 파드명+서비스명 으로 도메인명이 생성되어, 이를 통해 접근 가능
- Headless Service: ClusterIP의 속성을 None으로 지정하면 서비스 ip가 생성되지 않음
- 파드 생성 시, hostname(해당 파드 도메인명)과 subdomain(연결할 서비스명) 지정 필요

3) Endpoint
- 서비스와 파드 연결 시 라벨 이용 => k8s는 서비스와 동일한 이름의 엔드포인트를 만들고, 내부에 파드 접속정보 생성
- 라벨을 이용하지 않고 엔드포인트를 만들어 연결고리를 직접 관리할 수도 있음(내외부 모두 가능)
=> ip주소를 사용하므로, 별도 변경관리 필요
4) ExternalName
- ExternalName 서비스 생성 후 특정 외부 도메인명을 지정할 수 있고, DNS Sever를 통해 ip 확인 가능
- 파드는 해당 서비스의 도메인명을 통해 접근하는 구조이므로, 연결할 외부 서버가 변경되면 서비스 도메인명만 바꾸면 됨

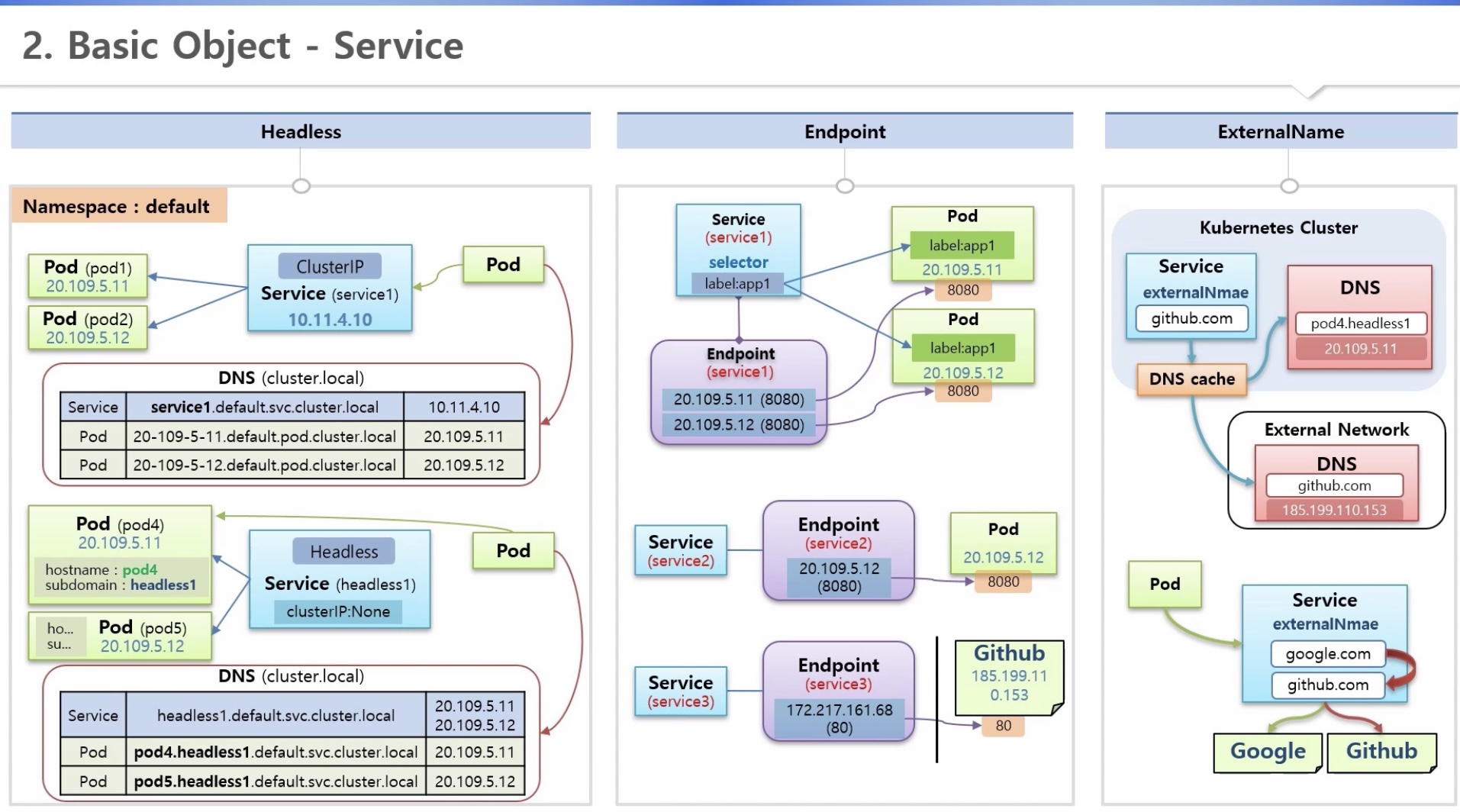
2. Basic Object - Service 실습
[참고] https://kubetm.github.io/k8s/07-intermediate-basic-resource/service/
Service
Headless, Endpoint, ExternalName
kubetm.github.io
0) Domain Server
- 마스터 노드에서 해당 파드 컨테이너로 들어가기(exit 로 나오기)
kubectl exec request-pod -it /bin/bash
- DNS 로 ip 조회(nslookup)
nslookup clusterip1
nslookup clusterip1.default.svc.cluster.local
- 서비스 DNS를 통해 원하는 파드에 접근(curl)
curl clusterip1/hostname
curl clusterip1.default.svc.cluster.local/hostname
1) Headless
- 마스터 노드에서 해당 파드 컨테이너로 들어가기(exit 로 나오기)
kubectl exec request-pod -it /bin/bash
- DNS 로 ip 조회(nslookup)
nslookup headless1 => 연결된 전체 파드의 ip 호출
nslookup pod-a.headless1 => 원하는 파드 ip 호출
nslookup pod-b.headless1
- 서비스 DNS를 통해 원하는 파드에 접근(curl)
curl pod-a.headless1:8080/hostname
curl pod-b.headless1:8080/hostname
2) Endpoint
- endpoint 상세조회
kubectl describe endpoints endpoint1
- selector와 label 없이 파드와 서비스 연결하기(파드의 ip로 endpoint를 생성하면 서비스에 들어감)
curl endpoint2:8080/hostname
- Github - Ip Address
nslookup https://www.github.com
curl -O 185.199.110.153:80/kubetm/kubetm.github.io/blob/master/sample/practice/intermediate/service-sample.md
- 확인된 ip로 endpoint 생성 후 서비스명을 통해 접근
curl -O endpoint3/kubetm/kubetm.github.io/blob/master/sample/practice/intermediate/service-sample.md
3) ExternalName
- ExternalName 서비스를 통한 접근
curl -O externalname1/kubetm/kubetm.github.io/blob/master/sample/practice/intermediate/service-sample.md
* 버전 1.11 이후, 기존 kube-dns의 일부 보안 및 안정성 문제를 해결하기 위해 CoreDNS 를 도입
2. Basic Object - Volume
* 내부망 관리
1) hostpath, local: 노드가 기본적으로 가지고 있는 볼륨
2) On-Premise storage service: storageos, ceph, GlusterFS 등 솔루션
3) NFS: 다른 서버를 볼륨 자원으로 사용
* 외부망 관리
CSP 에 스토리지를 두고 클러스터와 연결하여 사용
[기초편]
1) PV(PersistentVolume) 생성: 저장용량과 accessmode 결정 후 볼륨과 연결해둠
2) PVC(PersistentVolumeClaim): 사용자가 저장용량과 accessmode 결정 후 PVC를 만들면 k8s가 적절한 PV와 연결
3) 파드는 PVC를 통해 볼륨 이용
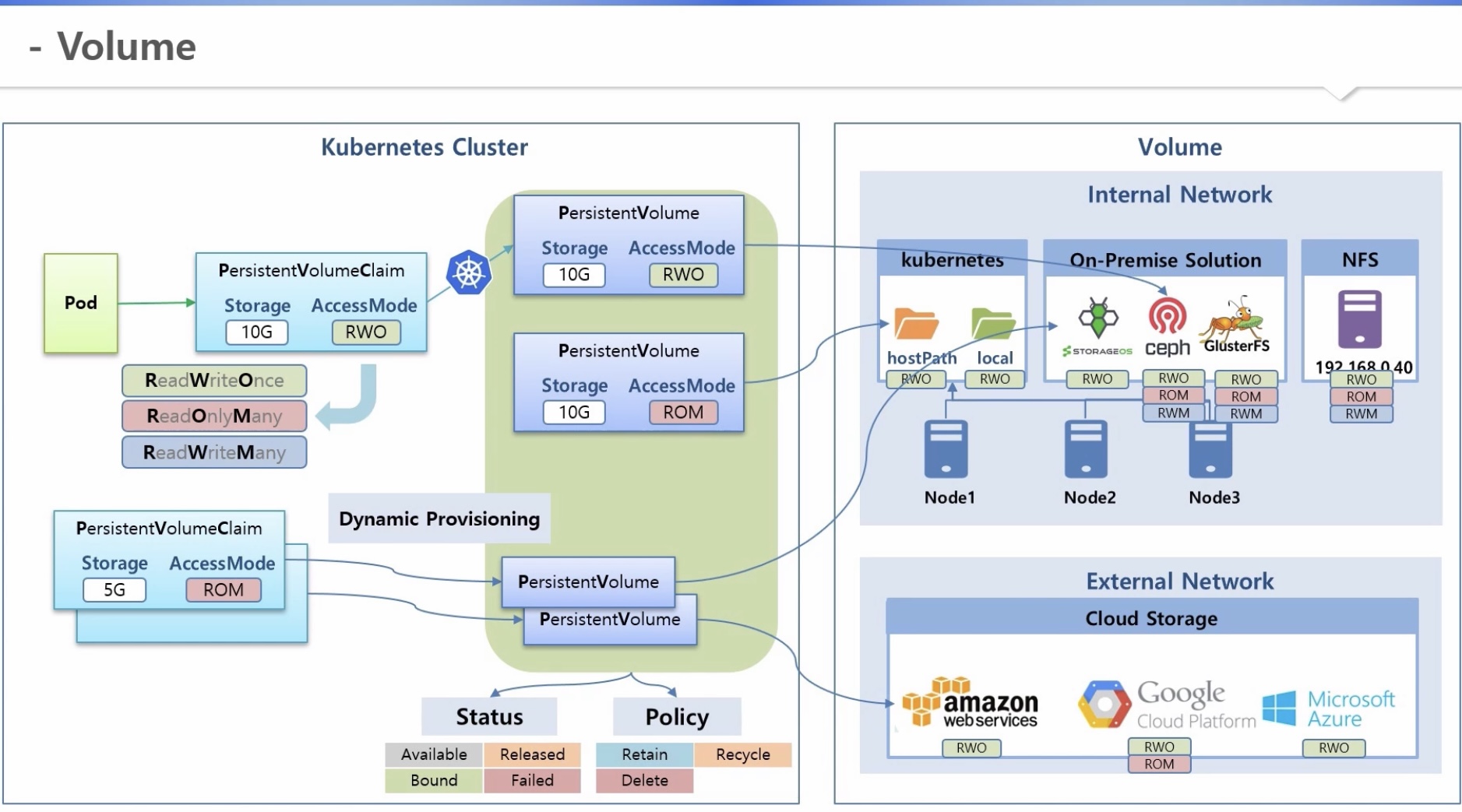
[중급편]
1) Dynamic Provisioning
- 사용자가 PVC를 만들면 k8s가 알아서 PV를 만들고 볼륨과 연결해 줌
- 해당 기능을 지원해주는 스토리지 솔루션 설치 필요 => StorageClass 오브젝트가 생성됨
- PVC에 StorageClassName을 넣어주면 자동으로 그에 맞는 PV를 만들어서 해당 솔루션과 연결
- 디폴트 StorageClass를 설정해 두면, StorageClassName을 지정하지 않을 경우 자동으로 연결
2) Status & ReclaimPolicy
a. PV Status
- available: 최초 생성되어 아무것도 연결되지 않았을 때
- failed: PV와 볼륨 간 연결에 문제가 생긴 경우
- Bound: PVC와 연결된 경우
(실제 파드가 연결된 후에 데이터가 생성되며, 파드만 삭제되는 경우 데이터는 그냥 유지됨)
- Released: PVC와 연결이 끊어진 경우
b. ReclaimPolicy(PVC와 연결이 끊어질 때 정책)
- Retain(디폴트): 데이터는 보존되나 재사용 불가 (PV status = Released)
- Delete(스토리지 클래스로 자동 생성된 경우, 디폴트): 함께 삭제되어 재사용 불가 (데이터는 볼륨에 따라 보존 여부 결정)
- Recycle: 데이터는 삭제되나 재사용 가능 (Deprecated, PV status = Available)
* Recycle 정책은 /tmp/로 시작하는 Path에서만 가능

2. Basic Object - Volume 실습
[참고] https://kubetm.github.io/k8s/07-intermediate-basic-resource/volume/
Volume
Dynamic Provisioning, StorageClass, Status, ReclaimPolicy
kubetm.github.io
1) 사전 구성 - StorageOS 설치 및 StorageClass 생성
1-1) StorageOS Operator 설치
- StorageOS Operator 설치
kubectl apply -f https://github.com/storageos/cluster-operator/releases/download/1.5.0/storageos-operator.yaml
- 설치 확인
kubectl get all -n storageos-operator
=> 파드, 서비스, 디플로이먼트, 리플리카셋이 생성됨
- Depolyment 수정
kubectl edit deployments.apps storageos-cluster-operator -n storageos-operator
=> spec.containers.env의 DISABLE_SCHEDULER_WEBHOOK의 Value를 true로 설정
- 관리 계정을 위한 Secret 생성 (username 및 password를 Base64문자로 만들기)
echo -n "admin" | base64
echo -n "1234" | base64
- 관리 계정을 위한 Secret 생성 (Base64문자로 만든 계정 이용) - 커맨드는 링크 참고
1-2) StorageOS 설치
- StorageOS 설치 트리거 생성 - 커맨드는 링크 참고
- 설치 확인
kubectl get all -n storageos
=> 파드, 서비스, 데몬셋, 디플로이먼트, 리플리카셋이 생성됨
* 서비스가 클러스터 ip로 생성되어
a. external-ip를 수정하여 접속이 가능하도록 변경 (방법 1)
- Dashboard 접속을 위한 Service 수정
kubectl edit service storageos -n storageos
=> spec에 externalIPs와 Master IP 추가
b. 클러스터 터입을 NodePort로 변경 (방법2)
- kubectl edit service storageos -n storageos
=> type을 NodePort로 변경
- 스토리지 솔루션 대시보드 접속
http://192.168.0.30:5705/
1-3) Default StorageClass 추가
- annotations에 디폴트를 지정하여 생성
- StorageClass 확인
kubectl get storageclasses.storage.k8s.io
=> 디폴트 스토리지클래스와 OS 생성 시 자동으로 생성된 스토리지클래스(fast) 확인
2) Dynamic Provisioning
2-1) PV 생성 (storageClassName: "")
=> 알맞은 PVC 에 연결됨 (PVC에 파드가 연결될 때 자동으로 볼륨 연결)
a. 파드 생성 후 연결, 데이터 생성 => 파드가 생성된 노드에 볼륨 생성
cd /mount1
touch file.txt
b. 해당 노드로 접속 후 확인
cd /mnt
ls => hostpath 확인
cd hostpath/
ls => 기 생성한 파일 확인
2-2) PV 생성 (storageClassName: "fast")
=> 지정한 스토리지 클래스를 적용하여 생성 후 자동으로 볼륨 연결
2-3) PV 생성 (storageClassName 없음)
=> 디폴트 스토리지 클래스를 적용하여 생성 후 자동으로 볼륨 연결
* Get All Objects in Namespaces
kubectl get all -n storageos-operator
* Force Deletion (리소스가 잘 삭제되지 않는 경우 강제 수행 => 기본 커맨드 끝에 "--force" 추가)
kubectl delete persistentvolumeclaims pvc-fast1 --namespace=default --grace-period 0 --force
kubectl delete persistentvolume pvc-b53fd802-3919-4fb0-8c1f-02221a3e4bc0 --grace-period 0 --force
2. Access to the K8s API 개요

- K8s API 서버를 통해서만 자원을 만들고 조회할 수 있음
1) Authentication: k8s api 서버로 접근하는 방법
[User Account]
- 외부에서 api 서버 접근 시
a. https: 일반적으로는 인증서를 가진 경우에만 보안 접근 가능
b. http: 관리자가 프록시를 열어준 경우에는 인증서 없이 접근 가능
- kubectl은 내외부 모두 설치 가능하며, 외부에 설치한 경우 config 기능을 활용하여 원하는 클러스터에 연결 가능
- ServiceAccount 로도 외부에서 접근 가능
[Service Account]
- 파드가 api 서버로 접근하는 방법
2) Authorization: 내가 필요한 자원을 조회할 수 있는 권한 제어
2. Authentication
1) X509 Client Certs
- kubeconfig: 클러스터에 접근할 수 있는 정보 관리 (인증서 등)
- kubectl 설치 시, kubeconfig 를 통째로 복사하여 전체 사용이 가능하도록 설정함
=> kubectl을 통해 api 서버 접근 가능 (프록시를 열어주는 경우, 인증서 없이도 접근 가능)
2) kubectl
- 접근하고자 하는 클러스터의 kubeconfig 정보가 모두 있어야 함
- kubeconfig: 접근하고자 하는 클러스터의 contexts 이용
a. clersters: 클러스터 등록 (이름, 연결정보, 인증서)
b. users: 사용자 등록 (이름, 개인키, 인증서)
c. contexts: clersters 와 users 연결 (컨텍스트 이름, 클러스터와 사용자 이름)
3) Service Account
- 네임스페이스 생성 시, 디폴트 서비스 어카운트가 자동으로 생성됨
- Secret: 서비스 어카운트 생성 시 하위에 자동 생성 (인증서, 토큰값)
- 파드를 생성하면 이 서비스 어카운트에 연결되고, Secret의 토큰값을 이용해 api서버에 접근 가능
* 토큰값만 알면 사용자도 api서버에 접근 가능

2. Authentication 실습
[참고] https://kubetm.github.io/k8s/07-intermediate-basic-resource/authentication/
Authentication
X509 Certs, Kubectl, ServiceAccount
kubetm.github.io
1) X509 Client Certs
1-1) kubeconfig 인증서 확인
- 마스터 노드에서 kubeconfig 확인
cat /etc/kubernetes/admin.conf
=> 클러스터 인증서, 사용자 개인키와 인증서 등
- 클라이언트 인증서 및 키 가져오기(decode로 변환)
grep 'client-certificate-data' /etc/kubernetes/admin.conf | head -n 1 | awk '{print $2}' | base64 -d
grep 'client-key-data' /etc/kubernetes/admin.conf | head -n 1 | awk '{print $2}' | base64 -d
=> 별도 저장해두기
1-2) Https API (Client.crt, Client.key)
a. postman
- 설정 변경
Settings > General > SSL certificate verification > OFF => api가 날라감
Settings > Certificates > Client Certificates > Host, CRT file, KEY file => 인증서 등록
- https로 노드 정보 조회
https://192.168.0.30:6443/api/v1/nodes => 노드 리스트 정보 조회 가능
b. curl
curl -k --key ./Client.key --cert ./Client.crt https://192.168.0.30:6443/api/v1/nodes
1-3) kubectl config 세팅
- kubeadm / kubectl / kubelet 동시 설치
yum install -y --disableexcludes=kubernetes kubeadm-1.15.5-0.x86_64 kubectl-1.15.5-0.x86_64 kubelet-1.15.5-0.x86_64
- admin.conf 인증서 복사
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
- Kubectl Proxy 띄우기(모든 호스트에서 접속 가능)
nohup kubectl proxy --port=8001 --address=192.168.0.30 --accept-hosts='^*$' >/dev/null 2>&1 &
1-4) HTTP API 호출 (Proxy)
a. postman
http://192.168.0.30:8001/api/v1/nodes
b. curl
curl http://192.168.0.30:8001/api/v1/nodes
2) kubectl
2-1) 클러스터 A, B kubeconfig 파일 합치기: clusters, users, contexts
/etc/kubernetes/admin.conf
2-2) kubectl CLI
- kubectl download
https://kubernetes.io/docs/tasks/tools/install-kubectl/
- windows (별도의 설치과정 필요 없음)
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.18.0/bin/windows/amd64/kubectl.exe
- context 지정
kubectl config use-context context-a
kubectl get nodes => 노드 확인
3) Service Account
3-1) Namespace 생성
kubectl create ns nm-01
3-2) ServiceAccount & Secret 확인
kubectl describe -n nm-01 serviceaccounts
kubectl describe -n nm-01 secrets
3-3) 파드 생성 후, Https API 호출 (Token) - 기 등록함 인증서 삭제 후 진행 필요
a. http
- 헤더 정보 확인 => key: Authorization / value: "Bearer " + TOKEN값
- api 접근 확인
https://192.168.0.30:6443/api/v1
https://192.168.0.30:6443/api/v1/namespaces/nm-01/pods/ (권한이 없어서 에러남)
b. curl
curl -k -H "Authorization: Bearer TOKEN" https://192.168.0.30:6443/api/v1
curl -k -H "Authorization: Bearer TOKEN" https://192.168.0.30:6443/api/v1/namespaces/nm-01/pods/
* curl: 서버와 통신할 수 있는 커맨드 명령어 툴로서, url로 할 수 있는 건 모두 가능
https://m.blog.naver.com/govlepdl1378/222446539563
[Linux] CURL 이란?
CURL(Client URL) 이란? 서버와 통신할 수 있는 커맨드 명령어 툴이며 웹 개발에 많이 사용되고 있...
blog.naver.com
* postman: 편리한 REST API 설계, 개발, 테스팅 기능을 툴로 제공하고, 결과를 공유하여 개발 생산성을 높여주는 플랫폼
https://meetup.toast.com/posts/107
Postman 개요 / 설치 / 사용법 / 활용 방법 : NHN Cloud Meetup
Postman
meetup.toast.com
2. Authorization
1) RBAC (Role, RoleBinding) Overview
- Role: 네임스페이스 내 자원들의 권한 제어를 위한 것으로 여러가지 케이스로 생성 가능
- RoleBinding: 롤과 서비스 어카운트 연결(1:N)을 의한 것으로 역시 여러가지 케이스로 생성 가능
=> 서비스 어카운트는 연결된 롤의 권한으로 api서버에 접근
- ClusterRole: 클러스터 내 자원들의 권한 제어를 위한 것
* ClusterRole을 RoleBinding과 연결시키면, 자신의 네임스페이스 내부 자원만 사용 가능
(전체 네임스페이스에서 공통으로 사용하는 롤은 위와같이 관리하는 것이 효율적)
- ClusterRoleBinding: 클러스터 롤과 서비스 어카운트 연결(1:N)을 의한 것

2) RBAC (Role, RoleBinding) Detail
[자신의 Namespace 내에 Pod들만 조회할 수 있는 권한]
- Role
a. apiGroups: CoreAPI(파드, 서비스 등)인 경우 공란, 그 외엔 지정 필요 (ex: job => batch)
b. resources: 리소스 종류 (ex: pods, jobs)
c. verbs: 권한 종류 및 범위 (ex: get, list)
- RoleBinding
a. RoleRef: 롤과 연결
b. subjects: SA(서비스어카운트)와 연결
=> SA에 붙은 Secret의 토큰값을 이용하여 해당 api서버에 접근 가능
[모든 Namespace 내에 Object들에 대해 모든 권한을 부여]
- ClusterRole
a. apiGroups: [*]
b. resources: [*]
c. verbs: [*]
=> ClusterRoleBinding을 이용하여 상기 클러스터롤과 내 SA를 연결하면, 토큰값을 이용해 모든 자원에 접근 가능
2. Authorization 실습
[참고] https://kubetm.github.io/k8s/07-intermediate-basic-resource/authorization/
Authorization
RBAC, Role, RoleBinding
kubetm.github.io
1) 자신의 Namespace 내에 Pod들만 조회할 수 있는 권한
- 롤: 파드만 조회 가능하도록 권한 생성
rules: apiGroups: [""] / verbs: ["get", "list"] / resources: ["pods"]
- 롤바인딩: 롤과 SA 연결
- SA Secret 토근을 통한 파드 https api 호출
a. postman
header Authorization : "Bearer " + TOKEN값
https://192.168.0.30:6443/api/v1/namespaces/nm-01/pods/
b. curl
curl -k -H "Authorization: Bearer TOKEN값" https://192.168.0.30:6443/api/v1/namespaces/nm-01/pods/
- SA Secret 토근을 통한 서비스 https api 호출 (권한 없음) by postman
https://192.168.0.30:6443/api/v1/namespaces/nm-01/service
=> 해당 SA에는 서비스에 대한 조회 권한이 없다고 리턴
2) 모든 Namespace 내에 Object들에 대해 모든 권한을 부여
- 클러스터롤: 클러스터 내 전체 리소스 조회 가능하도록 권한 생성
rules: apiGroups: ["*"] / verbs: ["*"] / resources: ["*"]
- 클러스터롤바인딩: 클러스터롤과 SA 연결
- SA Secret 토근을 통한 서비스 https api 호출
a. postman
header Authorization : "Bearer " + TOKEN값
https://192.168.0.30:6443/api/v1/namespaces/nm-01/service
b. curl
curl -k -H "Authorization: Bearer TOKEN값" https://192.168.0.30:6443/api/v1/namespaces/nm-01/service
- SA Secret 토근을 통한 노드 https api 호출 by postman
https://192.168.0.30:6443/api/v1/nodes
=> 이제 네임스페이스 내 파드, 서비스 및 클러스터 노드도 모두 조회됨
2. k8s Dashboard
1) v1.10.1(as-is) => 보안에 취약함
- proxy를 통해 인증 없이 api 서버 접근 가능 by http
- 로그인: skip 가능
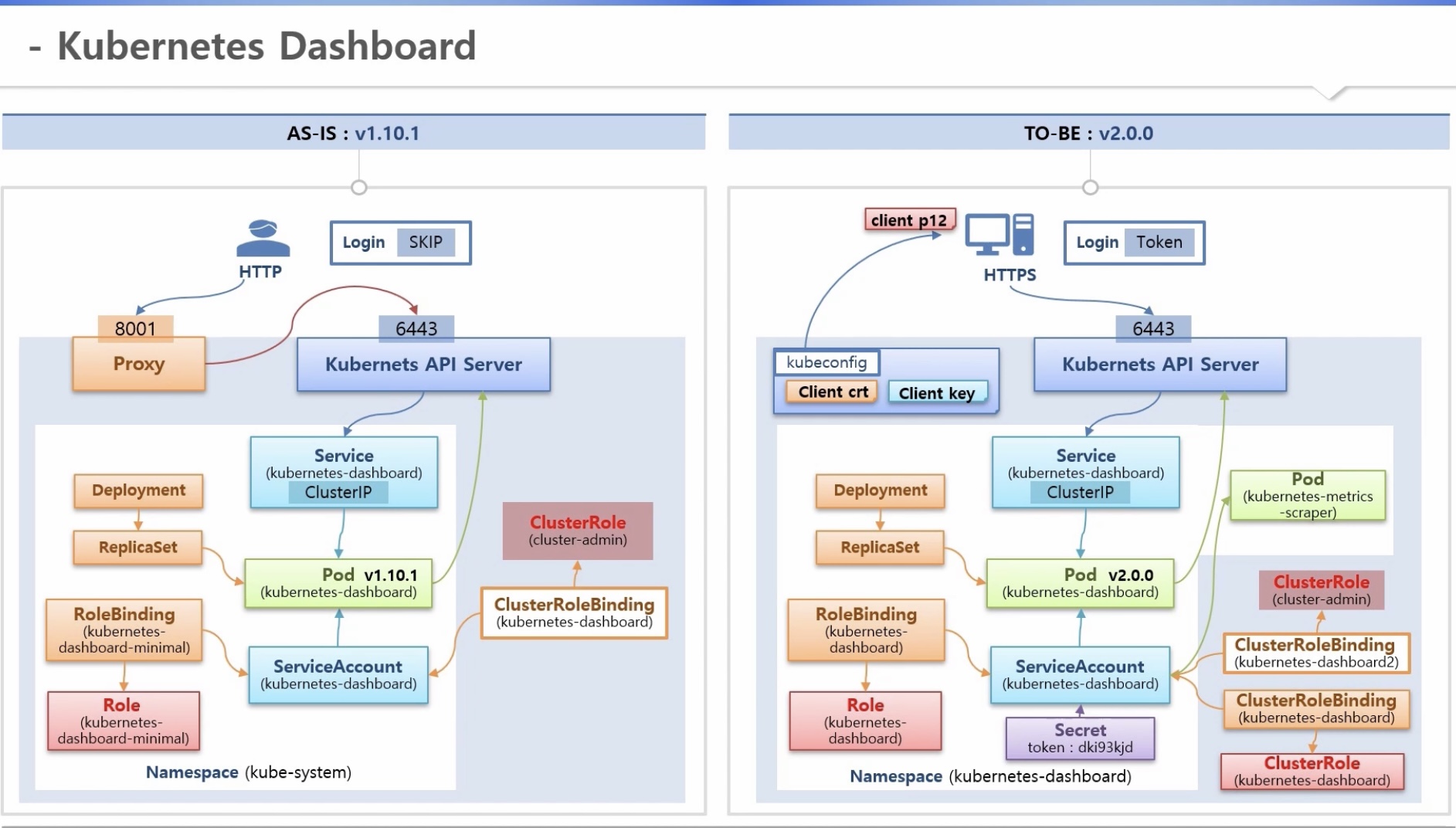
2) v2.0.0(to-be) => 보안 강화
- proxy 없이 api 서버 접근 by https
a. kubeconfig 파일: 개인키, 인증서 추가
b. 상기 정보를 이용하여 내 pc에 인증서 등록
- k8s-metrics-scraper 파드 이용(신규): 메트릭스 서버가 설치된 경우 노드나 파드의 성능 정보를 그래프로 확인 가능
(별도의 클러스터롤과 클러스터롤바인딩 연결 필요)
- 로그인: SA의 Secret 토큰값 이용
2. k8s Dashboard 실습
[참고] https://kubetm.github.io/k8s/07-intermediate-basic-resource/dashboard/
Dashboard
Kubeconfig, Token
kubetm.github.io
1) Dashboard 2.0.0 설치
- v1.10.1(as-is) 대시보드 삭제
kubectl delete -f https://kubetm.github.io/documents/appendix/kubetm-dashboard-v2.0.0.yaml
- v2.0.0(to-be) 대시보드 설치
(설치가이드: https://github.com/kubernetes/dashboard)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
- 클러스터롤바인딩 생성(클러스터롤은 기 존재)
- 토큰 확인
kubectl -n kubernetes-dashboard get secret kubernetes-dashboard-token- \-o jsonpath='{.data.token}' | base64 --decode
=> 상기 커맨드 "dashboard-token- " 에서 우측 공란에서 탭을 치면 토큰 이름이 완성됨
- 내 PC에 인증서 설치
grep 'client-certificate-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> client.crt
grep 'client-key-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> client.key
=> 개인키와 인증서 파일 생성
openssl pkcs12 -export -clcerts -inkey client.key -in client.crt -out client.p12 -name "k8s-master-30"
=> kubecfg.p12 파일(인증서) 생성 후 내 PC에서 인증서 등록
- Https 로 Dashboard 접근 후 Token 으로 로그인
https://192.168.0.30:6443/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/#/login
=> 인증서를 선택하면 로그인 화면이 나오고, 토큰을 이용하여 로그인 가능
(메트릭스 서버가 설치된 경우 노드나 파드의 성능 정보를 그래프로 확인 가능)

섹션 3. [중급편] 컨트롤러
3. Statefulset
1) Stateless Application
- ex: 웹서버 (apache, nginx, iis 등)
- 앱이 여러개 배포되더라도 다 서비스의 역할을 함
=> 앱 하나가 죽으면, 단순히 동일한 역할을 하는 앱을 복제해서 새로 생성하면 됨(이름 변경되어도 됨)
- 하나의 볼륨을 함께 사용할 수 있음(없어도 됨)
- 대체로 사용자가 접속하여 사용하며, 트래픽은 분산되도록 설계
2) Stateful Application
- ex: 디비서버 (rdb, nosqldb)
- 각 앱마다 역할이 다름
a. primary: 메인디비(read/write)
b. secondary: 예비디비(read)
c. arbiter: 메인디비가 죽으면 예비디비가 메인다비 역할을 할 수 있도록 변경
=> 앱 하나가 죽으면, 반드시 동일한 역할을 하는 동일 이름의 앱이 생성되어야 함
- 각 앱마다 별도의 볼륨을 사용해야 함
- 대체로 내부시스템이 접속하여 사용하며, 트래픽은 각 앱의 특징(목적)에 맞게 들어가야 함

3) StatefulSet Controller
a. ReplicaSet
- 파드 생성 시 랜덤 이름 생성
- replicas 증가 시, 동시에 랜덤 이름으로 파드 생성
- 파드가 삭제되어 재 생성시, 새 이름으로 생성
- replicas=0 으로 변경하면, 동시에 삭제
b. StatefulSet
- 파드 생성 시 index를 매겨 이름으로 생성
- replicas 증가 시, index를 하나씩 올린 이름으로 순차적으로 파드 생성
- 파드가 삭제되어 재 생성시, 기존 이름으로 생성
- replicas=0 으로 변경하면, index가 높은 파드부터 순차적으로 삭제
4) PersistentVolumeClaim, Headless Service
a. ReplicaSet
- PVC가 미리 생성되어 있어야 하고, 리플리카셋 템플릿에 기 생성된 PVC를 지정 => 파드 생성 시 해당 PVC에 연결됨
- replicas 증가 시, 모든 파드는 템플릿에 설정된 동일한 PVC로 연결됨
- PVC의 AccessMode=RWO 인 경우, 모든 파드는 PVC와 동일한 노드에 있어야 하므로 템플릿에 노드셀렉터 지정
b. StatefulSet
- volumeClime 템플릿이 별도로 존재 => 파드 생성 시 동적으로 새로운 PVC가 생성되어 연결됨
- replicas 증가 시, 파드가 생성될 때마다 새로운 PVC가 생성되어 연결됨
- 파드가 삭제되어 재 생성시, 기존에 사용하던 PVC에 연결됨
- PVC가 동적으로 생성되므로, 각 파드는 전체 노드에 균등하게 할당됨
- replicas=0 으로 변경하면, 파드는 삭제하지만 PVC는 삭제하지 않음
- ServiceName 속성으로 서비스 지정
=> 해당 이름과 동일한 Headless 서비스를 생성하면 특정 파드에서 도메인명을 이용하여 원하는 파드에 연결 가능

3. Statefulset 실습
[참고] https://kubetm.github.io/k8s/08-intermediate-controller/statefulset/
Statefulset
Pod, PersistentVolume, Headless Service
kubetm.github.io
1) StatefulSet Controller
2-1) PersistentVolumeClaim - ReplicaSet
- nodeSelector 옵션을 빼고 생성하는 경우, PVC와 다른 노드에 생성된 파드는 해당 PVC에 연결되지 못해 에러 발생
- 동일한 PVC를 사용하므로, 모든 파드에서 데이터 공유
2-2) PersistentVolumeClaim - StatefulSet
- 파드 템플릿과 PVC 템플릿의 볼륨명이 다르면 생성되지 않음
- 파드명 생성 규칙: StatefulSet 이름 + index
- PVC이름 생성 규칙: 볼륨명 + 파드명
3) Headless Service
- 헤드리스 서비스에 연결된 파드의 ip주소 확인
nslookup stateful-headless
- 특정 파드에서 원하는 파드로 접근 by 도메인명
curl stateful-pvc-0.stateful-headless:8080/hostname
3. Ingress
[대표적인 usecases]
1) Service LoadBalancing
- L4 / L7 스위치(각 패스에 따라 서비스 ip 연결) 역할을 대신해줌
2) Canary Update
- 신규 버전 파드에 기존 버전 파드와 다른 서비스를 달고 ingress에 연결하면 서비스 별 할당되는 트래픽 비율 조정 가능
(신규 버전 테스트 시 활용 가능)

[구동 방식]
1) Ingress
- Host 도메인 및 패스 별 연결할 서비스 설정
- ingress를 추가하면 컨트롤러 파드가 해당 rule을 바로 인식하여 적용해줌
2) Ingress Controller
- Ingress 를 실행하는 구현체 (ex: nginx, kong 등)
- Deployment, ReplicaSet 을 통해 Ingress 파드가 생성됨
=> 해당 파드에 ingress rule을 설정하면 그에 따라 패스 별로 서비스 분산
- 외부 사용자가 접근할 때 ingress 파드를 가장 먼저 거칠 수 있도록 NodePort나 LoadBalancer 서비스 생성 필요 l

[기능 상세 - Ingress w.nginx]
1) Service Loadbalancing
- 각 업무 별로 파드와 서비스 구성
- ingress controller 설치 후, ingress 파드에 외부에서 접속 가능하도록 별도 서비스 연결
- 원하는 rule을 적용하여 ingress 생성
=> ingress에 설정된 패스 별로 서비스 분산
2) Canary Update
- 현재 운영중인 앱을 하나의 서비스로 연결하고, 테스트 앱은 별도의 서비스로 연결
- host명은 동일하고 서비스명만 다른 두개의 ingress 생성
- ingress weight 어노테이션: 서비스 별 트래픽 비율 조정
- ingress header 어노테이션: 특정 언어를 사용하는 트래픽만 할당
3) Https
- 인증서 관리(파드 자체에서 인증서 관리가 힘들 때 사용)
- ingress 파드 연결 시 443포트를 이용해야 함
- ingress 생성 시, tls 옵션으로 사용할 secretName 지정 => secret 오브젝트와 연결됨
=>도메인 이름 앞에 https를 붙여야만 접근 가능

3. Ingress 실습
[참고] https://kubetm.github.io/k8s/08-intermediate-controller/ingress/
Ingress
Service Loadbalancing, Canary Upgrade
kubetm.github.io
1) Nginx Controller
- nginx 설치
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.27.1/deploy/static/mandatory.yaml
- NodePort Service 생성&연결
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.27.1/deploy/static/provider/baremetal/service-nodeport.yaml
- 환경에 맞춰 해당 서비스의 nodeport 수정
2) Service Loadbalancing
3) Canary Upgrade
- OS에 hostname 등록
cat << EOF >> /etc/hosts
192.168.0.30 www.app.com
EOF
- hostname으로 기존에 운영 중인 앱 버전 확인
curl www.app.com:30431/version
- 테스트 ingress에 weight annotation 추가 후 트래픽 분산 확인
while true; do curl www.app.com:30431/version; sleep 1; done
- 테스트 ingress에 header annotation 추가 후 트래픽 분산 확인
curl -H "Accept-Language: kr" www.app.com:30431/version
4) SSL
- 인증서 생성
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=www.https.com/O=www.https.com"
- Secret 생성
kubectl create secret tls secret-https --key tls.key --cert tls.crt
- Windows HostName 등록
파일 위치 : C:\Windows\System32\drivers\etc\hosts
192.168.0.30 www.https.com
3. AutoScaler - HPA
1) HPA (Horizontal Pod AutoScaler)
- 파드의 개수 증가
- 원리
a. HPA를 replicaSet 컨트롤러에 연결
b. 파드 리소스에 한계가 왔을 때 자동으로 리플리카를 늘려 새로운 파드를 생성함으로써 부하 분산(scale out)
- 대상: 빠르게 기동되는 앱(문제 발생 전에 새로운 파드가 생성되어야 하므로), Stateless 앱
2) VPA (Vertical Pod AutoScaler)
- 파드의 리소스 증가
- 원리
a. VPA를 replicaSet 컨트롤러에 연결
b. 파드 리소스에 한계가 왔을 때 자동으로 파드를 재기동 시키면서 리소스를 증가시켜줌(scale up)
- 대상: stateful 앱
* HPA와 VPA 동사 사용 불가 => 아무것도 동작하지 않음
3) CA (Cluster AutoScaler)
- 클러스터에 노드 추가
- 원리
a. 스케쥴러가 파드를 할당하다가 더 이상 여유 노드가 없으면, CA에게 추가 요청
=> CA가 CSP 자원을 빌어 노드를 추가하면, 스케쥴러가 해당 노드에 신규 파드 할당
b. 스케쥴러가 로컬 노드 여유를 확인하면, CA에게 CSP 에 생성된 노드 삭제 요청
=> CA는 해당 노드 위의 파드를 로컬 노드로 옮긴 후 삭제

[HPA 아키텍쳐]
1) 마스터/노드 구성
a. 마스터(control plane component)
- Controller Manager 파드: 컨트롤러들이 쓰레드 형태로 돌아감
- kube-apiserver 파드: 모든 통신의 길목
b. 노드(worker node component)
- kubelet: 노드 내 파드 관리
2) 레플리카셋을 통한 신규 파드 생성 과정
- ReplicaSet 컨트롤러는 kube-apiserver를 통해 kubelet에게 파드 생성 요청
- kubelet은 컨트롤러 런타임(도커 등)에게 해당 파드에 들어갈 컨테이너를 만들어달라고 요청
- 도커가 해당 노드 위에 컨테이너 생성
3) HPA가 파드의 성능 정보를 모니터링하는 과정
- cAdvisor(Resource Estimator)가 도커로부터 파드의 memory, cpu 정보를 수집하여 kubelet과 공유
- addon component로 metric server를 설치하면
a. 각 노드의 kubelet으로부터 파드 memory, cpu 정보 수집
b. 수집한 정보를 kube-apiserver에 Resouce API형태로 등록하여 다른 컴포넌트들이 사용할 수 있게함
- HPA는 kube-apiserver를 통해 15초마다 파드 memory, cpu 정보 체크
=> 파드 리소스 사용율이 한계에 다다르면 리플리카를 하나 늘려 신규 파드 생산
- kubectl top 명령어를 통해 Resouce API에 접근하여 파드/노드의 리소스 현황 직접 조회 가능
- 프로메테우스 설치 시, 다양한 메트릭 수집 가능 => Custom API, External API
(ex: 파드로 들어오는 패킷 수, Ingress로 들어오는 리퀘스트양 등)

[HPA detail]
1) HPA 설정
- target: 대상 컨트롤러
- min/maxReplicas: 조정 가능 최소/최대 파드 수
- metrics
a. type: 대상 resource
* 기본: Pod / 기타: Object(ingress 등)
b. name: 대상 메트릭(cpu, memory 등)
c. 모니터링 기준(target)
. type: Utilization(사용 비율)
* 기타: AverageValue(평균값), Value(실제값)
. averageUtilization: 50
=> 해당 자원(파드)의 리퀘스트값을 기준으로 현재 사용량이 50%를 초과하면 replicas 증가
2) 계산식
- 모니터링 기준(target) = 파드 리퀘스트 평균 * 50%
- scale in/out 사이즈 = 현재 replicas * 현재 평균 리소스 사용량 / 모니터링 기준(target)

3. AutoScaler - HPA 실습
[참고] https://kubetm.github.io/k8s/08-intermediate-controller/hpa/
AutoScaler - HPA
HPA, VPA, CA
kubetm.github.io
3-1. Metrics Server 설치
3-1-1) Metrics Server 다운 및 설치
a. 설치
cd metrics-server
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml
b. Metrics Deployment 수정
- 컨테이너 args 에 `kubelet-insecure-tls` 와 `kubelet-preferred-address-types=InternalIP` 정보 추가
kubectl edit deployment metrics-server -n kube-system
==========================================
spec: containers:
args:
–cert-dir=/tmp
–secure-port=4443
–kubelet-insecure-tls
–kubelet-preferred-address-types=InternalIP
image: k8s.gcr.io/metrics-server-amd64:v0.3.6
imagePullPolicy: IfNotPresent name: metrics-server
c. 설치 확인
kubectl get apiservices |egrep metrics
------------------------
v1beta1.metrics.k8s.io kube-system/metrics-server True 28m
------------------------
d. 메트릭 값 확인 (1~2분 후): 노드의 현재 memory, cpu 상태 확인
kubectl top node
------------------------
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 485m 9% 4852Mi 32%
k8s-node1 413m 8% 4929Mi 33%
k8s-node2 554m 11% 4672Mi 31%
------------------------
3-2. HPA (Horizontal Pod Autoscaler)
3-2-1) Target Deployment (CPU) / Service 생성
3-2-2) HPA - Resource (Utilization) 생성
a. HPA 조회 (w옵션: 수치가 변경되면 바로 알려줌)
kubectl get hpa -w
b. 부하 생성
while true;do curl 192.168.0.30:30001/hostname; sleep 0.03; done
=> hpa에 지정한 Utilization(50%)보다 부하가 크면, 감소될 때까지 replicas로 파드 증가 (최대: maxReplicas)
=> ctrl + 'C' 명령으로 종료시킬 수 있음 => 부하 감소 => replicas로 파드 감소 (최소: minReplicas)
c. 기존에 걸었던 hpa 중지
kubectl delete horizontalpodautoscalers.autoscaling hpa-resource-cpu

3-2-3) Target Deployment (Memory) / Service 생성
3-2-4) HPA - Resource (AverageValue) 생성
a. HPA 조회 (w옵션: 수치가 변경되면 바로 알려줌)
kubectl get hpa -w
b. 부하 생성
while true;do curl 192.168.0.30:30002/hostname; sleep 0.03; done
=> hpa에 지정한 AverageValue(5Mi)보다 부하가 크면, 감소될 때까지 replicas로 파드 증가 (최대: maxReplicas)
=> ctrl + 'C' 명령으로 종료시킬 수 있음 => 부하 감소 => replicas로 파드 감소 (최소: minReplicas)
c. 기존에 걸었던 hpa 중지
kubectl delete horizontalpodautoscalers.autoscaling hpa-resource-cpu
섹션 4. [중급편] 아키텍쳐
4. 컴포넌트
1) k8s 아키텍쳐
a. 컴포넌트
- control plane component(마스터노드): 쿠버네티스 주요 기능 담당
- worker component(워커노드): 컨테이너 관리 기능
b. 네트워킹
- 파드 내 통신 / 파드 간 통신
- 서비스를 통한 통신
c. 스토리지
- 이용방법: hostpath, CSP, 3rd party 솔루션
- 종류: 파일, 블록, 오브젝트
d. 로깅(모니터링)
- 코어 파이프라인: api서버를 통해 파드 로깅
- 서비스 파이프라인: 별도의 플러그인을 통해 코어 파이프라인에서 원하는 부분만 선택적 로깅 후 ui로 공유

2) 파드, 디플로이먼트 생성과 연관된 컴포넌트 종류
a. 마스터 노드
* /etc/kubernetes/manifests: 컴포넌트 및 컨트롤러 생성을 위한 yaml 파일 존재
=> 기동 시 static 파드 형태로 띄움
- Etcd(k8s 내 db 역할), kube-scheduler, kube-apiserver
b. 워커 노드
- kublet, docker
3) 파드 생성 과정
a. 신규 파드 생성 요청(kubectl create)
b. 명령어가 kube-apiserver로 전달됨
c. kube-apiserver가 해당 파드 입력 정보를 Etcd에 저장
d. kube-scheduler
- 주기적으로 노드 상태 체크
- watch 기능으로 kube-apiserver를 통해 Etcd에 신규 요청 발생 여부 감시
=> 신규 요청 확인 시, 베스트 노드를 선택하여 Etcd 내 파드 정보에 노드 정보 추가
e. kublet
- watch 기능으로 kube-apiserver를 통해 Etcd에 신규 요청 발생 여부 감시
=> 내 노드 작업인 경우, 바로 가져와서 파드 생성
. 도커한테 컨테이너 생성 요청
. kube-proxy에게 네트워크 생성 요청 => 신규 컨테이너 통신 설비(?) 셋업

4) 디플로이먼트 생성 과정
a. controller manager: 여러 컨트롤러들이 쓰레드 형태로 돌아감
b. 신규 디플로이먼트 생성 요청 - replicas(2)(kubectl create)
c. 명령어가 kube-apiserver로 전달됨
d. kube-apiserver가 해당 디플로이먼트 입력 정보를 Etcd에 저장
e. controller manager > deployment 쓰레드
- watch 기능으로 kube-apiserver를 통해 Etcd에 신규 요청 발생 여부 감시
=> 신규 요청 확인 시, kube-apiserver에게 replicset 생성 요청
f. kube-apiserver가 해당 리플리카셋 입력 정보를 Etcd에 저장
g. controller manager > replicset 쓰레드
- watch 기능으로 kube-apiserver를 통해 Etcd에 신규 요청 발생 여부 감시
=> 신규 요청 확인 시, kube-apiserver에게 pod 생성 요청
h. kube-apiserver가 해당 파드 입력 정보를 Etcd에 저장
i. 3-d)와 동일
j. 3-e)와 동일
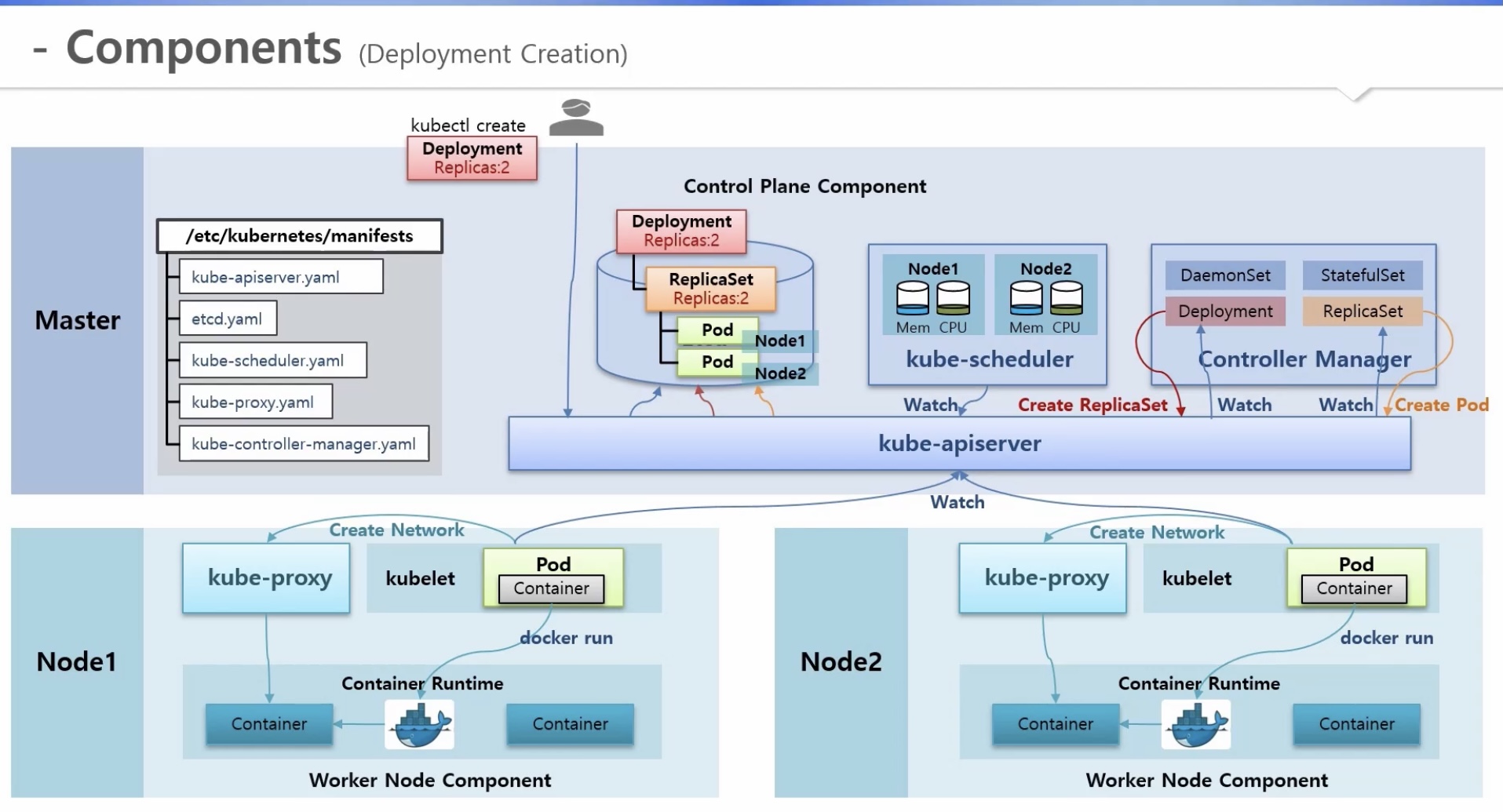
[참고] https://kubetm.github.io/k8s/09-intermediate-architecture/component/
Component Architecture
Kube-apiserver, Etcd, Kube-scheduler, Kube-proxy, Kube-controller-manager
kubetm.github.io
4. 네트워킹
[네트워킹 기본개념]
1) pod networking 영역
* 클러스터 설치시 pod-network-cidr(20.96.0.0/12)로 네트워크 대역 설정
a. Pod 안 container들 간의 네트워킹 방법
- pod 생성 시 내부에서 고유 ip를 가진 인터페이스(eth0 = 20.96.0.1)도 함께 생성됨
b. Pod 간 네트워킹 방법
- node마다 설치되는 network plugin에 의해 통신
- k8s default plugin: kubenet(컨테이너의 생성, 삭제, 마스터노드와 워커노드간의 통신역할 담당)
=> 네트워킹 기능이 제한적이라 잘 사용하지 않음
=> CNI(container network interface)를 통해 다양한 오픈소스 network plugin 설치 가능
* 강의에서는 이 중, calico 사용 예정 (csp 사용시 동일 plugin이더라도 다르게 동작 할 수 있음)

- network plugin 역할: 같은 노드 파트들 간의 통신 & 외부 네트워크(route/gateway)를 통한 타 노드 파트들 간의 통신
2) service networking 영역
* 클러스터 설치시 service-network-cidr(default: 10.96.0.0/12)로 네트워크 대역 설정
- pod에 service를 붙이면 service도 고유 ip 생성
=> 동시에 master node에서는
. kube-dns에 service 이름과 해당 ip에 대한 도메인 등록
. api-server가 worker node의 kube-proxy에 이 서비스의 ip가 어느 pod의 ip와 연결되어 있는지 정보 전달
- kube-proxy에 서비스 ip를 pod ip로 바꾸는 NAT 기능 필요
. Proxy mode: user space, iptables, ipvs
. service 별 설정이 존재하고, 해당 service 삭제 시 함께 삭제됨
- pod가 service 이름 호출 시 kube-dns가 service ip를 알려줌
- 이 service ip를 kube-proxy NAT영역(해당 service에 대한 pod 매핑정보 존재)으로 호출
=> 트래픽은 network plugin을 통해 해당 pod로 이동
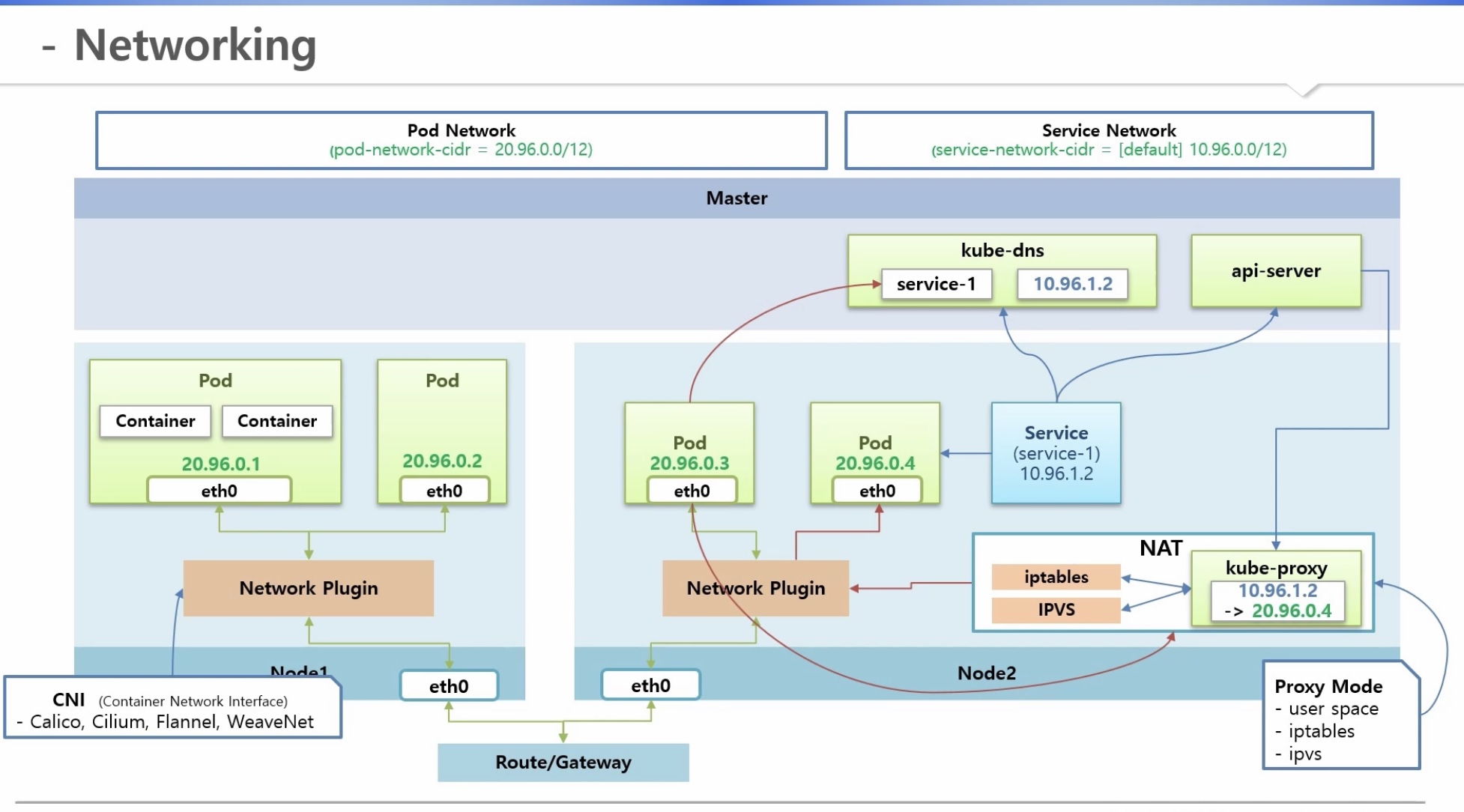
[파드 네트워크 상세 w. Calico]
1) pause container(pod network 담당)
- pod 생성 시 자동으로 생기는 네트워크 담당 컨테이너로서, 자체 interface(eth0) 및 ip 보유
- 해당 컨테이너의 네트워크 namespace는 파드 내의 모든 컨테이너가 함께 사용
- 파드내 컨테이너 간 구분은 포트 이용
* host network namespace
- 노드 네트워크 담당으로서, 자체 interface(eth0) 및 ip 보유
- 파드 생성 시, 가상 interface가 생성되고 해당 파드의 pause container와 서로 연결
- 원하는 파드늬 ip와 대상 컨테이너의 포트를 조합하여 주소 생성 => 20.111.156.66:8000
2) network plugin(cluster network 담당): host network 영역
2-1) kubenet 사용 시(잘 사용하지 않음 - 기본 네트워크 구성 이해용)
- 가상 네트워크를 cbr0이라는 container bridge에 포함 시킴
. bridge 네트워크 대역: 파드 네트워크 대역을 참고하여 보다 낮게 설정(20.96.1.0/24)
. 파드 네트워크 대역: 20.96.0.0/12(20.96.0.0 ~ 20.111.255.255)
. 파드 ip: bridge cidr 범위 내에서 생성(20.96.1.0 ~ 20.96.1.255) => 노드 당 최대 255개
- router(NAT): 파드 ip대역은 bridge로 보내고 그 외에는 위로 보냄
2-2) calico cni 사용 시
- 가상 네트워크를 router에 바로 연결
. router대역: 20.109.0.0/16
. pod ip: router cidr 범위 내에서 생성(20.109.0.0 ~ 20.109.255.255) => 노드 당 최대 255*255개
- 가상 네트워크 사이에 firewall을 생성하여 보안 기능 처리
- Overlay 네트워크 제공: 노드 간의 통신
. IPIP 방식
. VXLAN 방식
* 서로 노드가 다른 파드 D => 파드 B 로의 트래픽 이동 과정
a. 파드 D가 파드 B 의 ip로 호출
b. router 가상 인터페이스에서 파드 B가 내부에 존재하는지 확인하고, 없으면 Overlay 네트워크층(IPIP)으로 이동
c. 패킷을 파드 B가 존재하는 노드 ip로 변경(실제 파드 B ip는 내부에 숨겨져있음)
d. 패킷은 파드 B가 존재하는 노드의 Overlay 네트워크층(IPIP)으로 이동 후 숨겨온 파드 B ip로 변환
e. 트래픽은 파드 B ip 대역의 라우터로 전해진 후, 그에 맞는 가상 인터페이스를 지나 최종 목적지 파드 B 도착

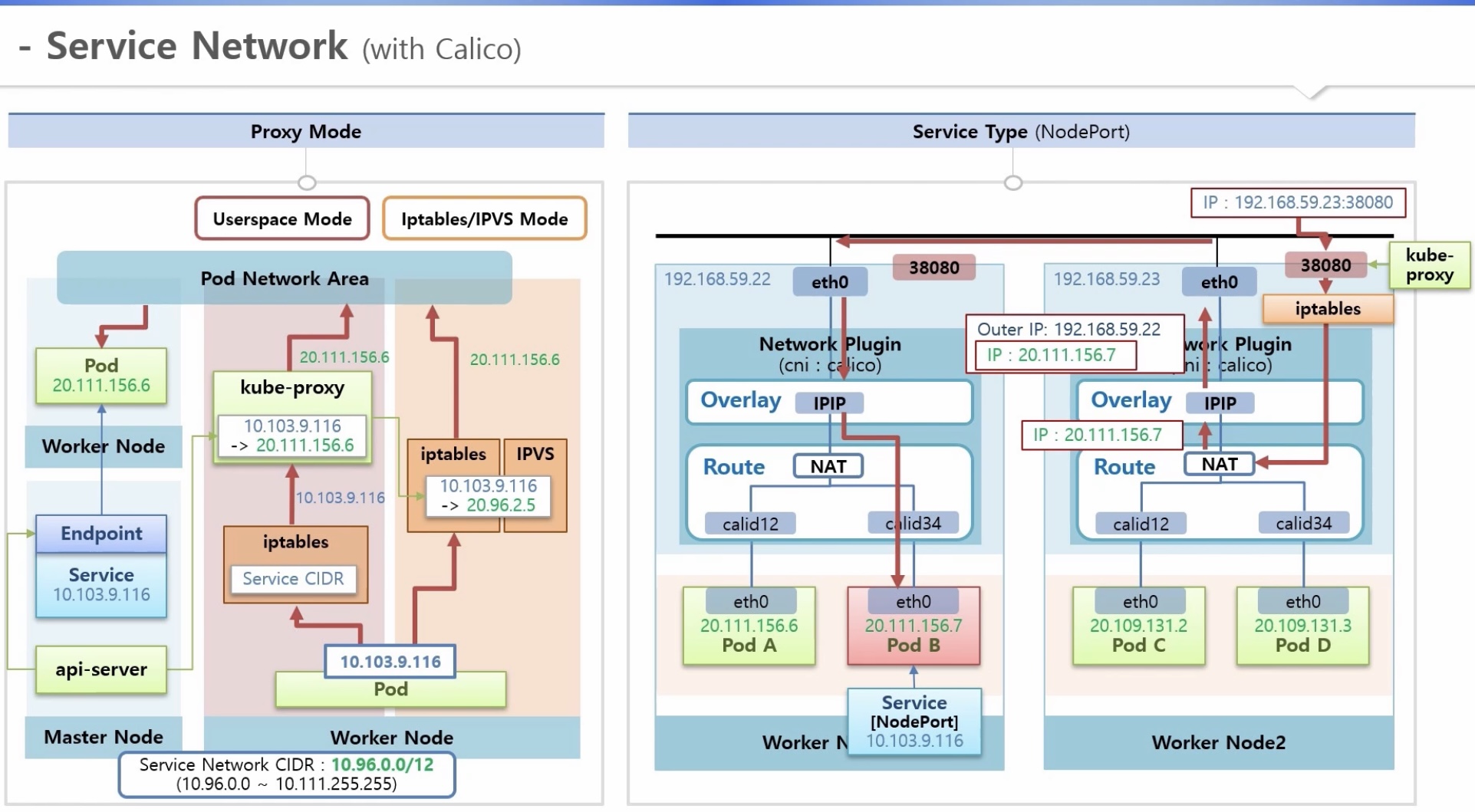
[서비스 네트워크 상세 w. Calico]
1) Proxy mode 별 트래픽 흐름
* 전제상황
- 정상 기동 된 파드에 서비스를 붙이면 중간에 endpoint라는 오브젝트가 생성되어 실제 연결 담당
- 서비스 ip: service network CIDR: 10.96.0.0/12 (10.96.0.0 ~ 10.111.255.255 범위 내에서 생성)
- api-server가 endpoint를 감시하다가 각 노드의 kube-proxy에게 해당 서비스와 파드 간의 ip매핑정보 전달
a. user space모드
- iptables로 들어오는 모든 트래픽은 service CIDR을 통해 모두 kube-proxy로 전달
- 파드에서 서비스 ip를 호출(트래픽) > iptables > kube-proxy 로 전달
- kube-proxy가 트래픽을 확인하여 해당 서비스에 매핑된 파드 ip로 변환되고, 파드 네트워크 영역으로 전달
* 단점: 모든 트래픽이 kube-proxy를 지나야 함 (성능면에서 좋지 않아 잘 사용되지 않음)
b. iptables(default)/ipvs 모드
- IPVS: iptables와 같은 기능을 하는 L4 로드발란서로서, 낮은 부하에서 성능 차이가 거의 없으나 높은 부하에서 고성능
- kube-proxy가 서비스-파드 ip매핑정보를 iptables/IPVS에 직접 등록
- 파드에서 서비스 ip를 호출(트래픽) > iptables/IPVS 에서 직접 파드 ip로 변환

2) service type 별 서비스 네트워크
2-1) clusterIP
* 서로 노드가 다른 파드 D => 파드 B 로의 트래픽 이동 과정
a. 파드 D 에서 파드 B의 서비스 ip로 트래픽 전달 (파드 B 에는 clusterIP 서비스 연결)
b. route의 NAT에서 해당 서비스의 파드(B) ip로 변환 => 내부에 없는 파드라면 Overlay 네트워크층(IPIP)으로 이동
c. 패킷을 파드 B가 존재하는 노드 ip로 변경(실제 파드 B ip는 캡슐화)
d. 패킷은 파드 B가 존재하는 노드의 Overlay 네트워크층(IPIP)으로 이동 후 캡슐 정보를 열어 파드 B ip로 변환
e. 트래픽은 파드 B ip 대역의 라우터로 전해진 후, 그에 맞는 가상 인터페이스를 지나 최종 목적지 파드 B 도착
2-2) nodePort
* 외부에서 파드 B 로의 트래픽 이동 과정
a. 외부에서 특정 hostIP의 포드로 파드 B의 트래픽 전달
(파드 B 에는 NodePort 서비스 연결 => 각 노드의 kube-proxy가 자신의 노드에 3만번대의 노드포트 오픈)
b. iptables에서 route의 NAT로 보내주고 해당 서비스의 파드(B) ip로 변환
=> 내부에 없는 파드라면 Overlay 네트워크층(IPIP)으로 이동
c~e. clusterIP와 상동
4. 네트워킹 실습
[참고] https://kubetm.github.io/k8s/09-intermediate-architecture/networking/
Networking Architecture
Pod Network(Pause Container, Network Plugin), Service Network(iptables, IPVS)
kubetm.github.io
1) Pod Network
1-1) Pause Container
a. 파드 생성 후, 해당 노드에서 Pause Container 생성 확인
- docker ps | grep pod-pause
=> 해당 노드에서 "pod-pause"가 들어간 컨테이너 조회 (컨테이너 id 조회)
b. Pause Container 인터페이스 확인
- docker inspect <container-id> -f "{{json .NetworkSettings}}"
=> 네트워크 셋팅 부분 조회 => <SandboxKey> 확인
- sudo ln -s /var/run/docker/netns /var/run/netns
- ip netns exec <SandboxKey> ip a
=> 해당 위치로 이동 후, SandboxKey에 대한 ip내용 조회 => 인터페이스 확인 가능

1-2) Calico Interface 확인
a. route 명령 설치 (노드 별)
- yum -y install net-tools
b. route로 Pod IP와 연결 되어 있는 인터페이스 확인
- route | grep cal
1-3) Pause Container Network Namespaces 확인
a. Pause Container와 타 Container간에 연결 확인
- docker inspect <container-id> -f "{{json .HostConfig.NetworkMode}}"
b. Docker Container NetworkMode
- NetworkMode - Sets the networking mode for the container.
Supported standard values are: bridge, host, none, and container:<name|id>.
Any other value is taken as a custom network’s name to which this container should connect to.
2) Pod Network - Calico
2-1) Pod (source) 생성 in 노드2
2-2) Pod (destination) 생성 in 노드1
2-3) Overlay Network(IP-in-IP) 트래픽 확인 in 마스터노드
a. Calico Overlay Network 확인
- kubectl describe IPPool
b. Cluster의 Pod Network CIDR 확인
- kubectl cluster-info dump | grep -m 1 cluster-cidr
=> cidr 동일
2-4) 트래픽 확인
a. tcpdump 패키지 설치 (노드 별)
- yum -y install tcpdump
b. route로 Pod IP와 연결 되어 있는 인터페이스 확인
- route | grep cal
c. 트래픽 확인 in 노드2 인터페이스 상태 확인(route-podD)
- tcpdump -i <interface-name>
d. 트래픽 발생 in 노드2 podD
- curl 20.111.156.72:8080/hostname
e. 호스트 인터페이스 리스트 조회 => 대상 인터페이스명 확인(overlay-노드2)
- ip addr
f. c, d 반복 => 트래픽 발생 및 확인 in 노드2 인터페이스 상태 확인(overlay-노드2)

g. 트래픽 발생 및 확인 in 노드1 인터페이스 상태 확인(노드2-노드1) => 목적지: 노드1
h. 트래픽 발생 및 확인 in 노드1 인터페이스 상태 확인(노드1-podB)=> 목적지: 노드1 podB
3) Service Network[clusterIP] - Calico
3-1) service (clusterIP) 생성
3-2) podD에서 해당 서비스로 트래픽 생성
- curl 10.107.94.97:8080/hostname
3-3) 트래픽 확인 in 노드2 인터페이스 상태 확인(route NAT-podD) => 목적지: 노드1
3-4) 트래픽 발생 및 확인 in 노드2 host 인터페이스 상태 확인(route NAT-overlay) => 목적지: 노드1 podB
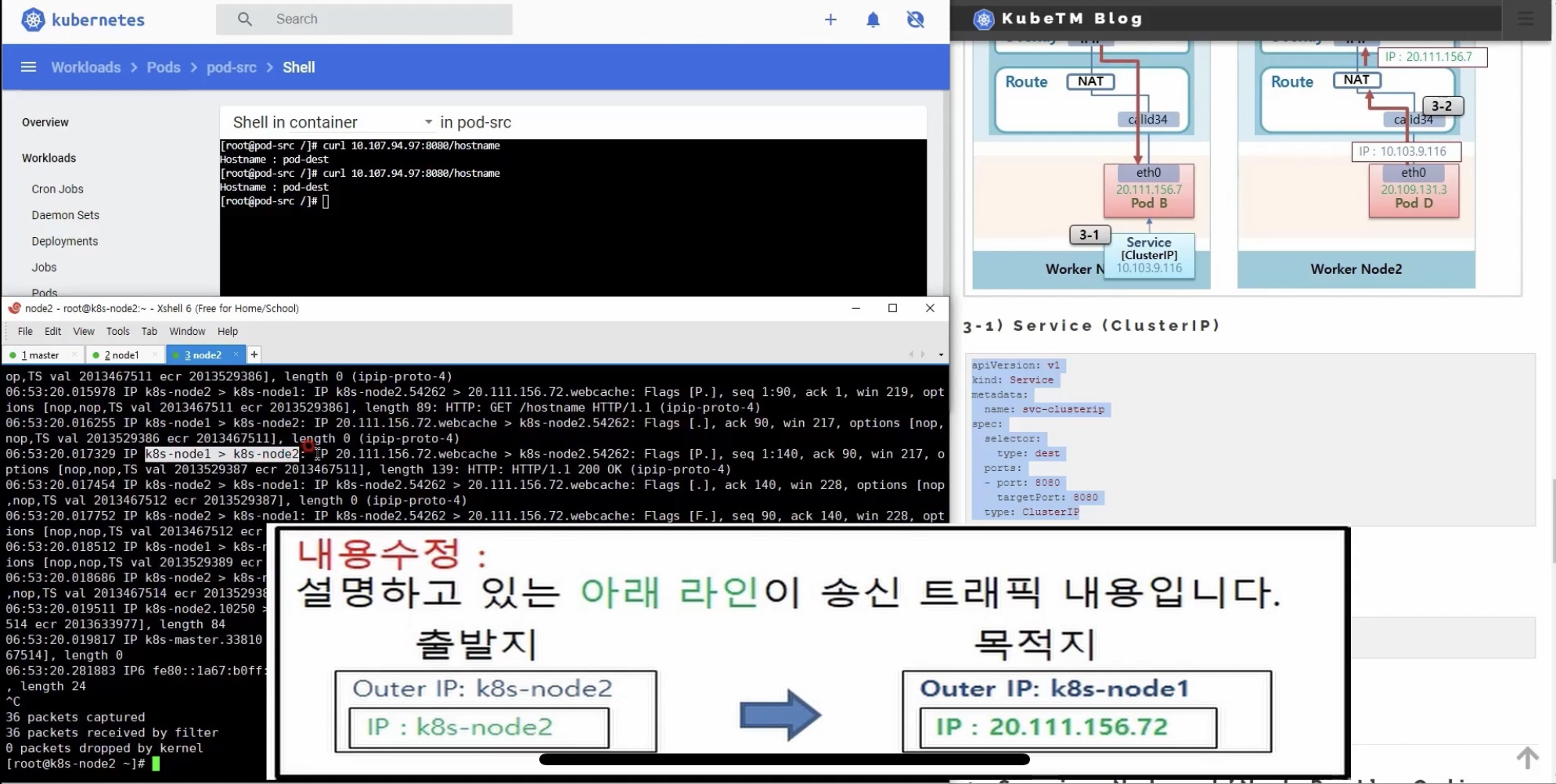
4) Service Network[NodePort] - Calico
4-1) service (NodePort) 생성
4-2) nodeport 확인
- netstat -anp | grep 31080
4-3) 트래픽 확인 in 노드2 인터페이스 상태 확인
- tcpdump -i <interface-name>
=> 마스터노드 => 31080 포트 => 네트워크 플러그인(파드ip로 변환): 목적지: 노드1
4-4) 마스터노드에서 해당 노드포트로 트래픽 생성
- curl 192.168.210.23:31080/hostname
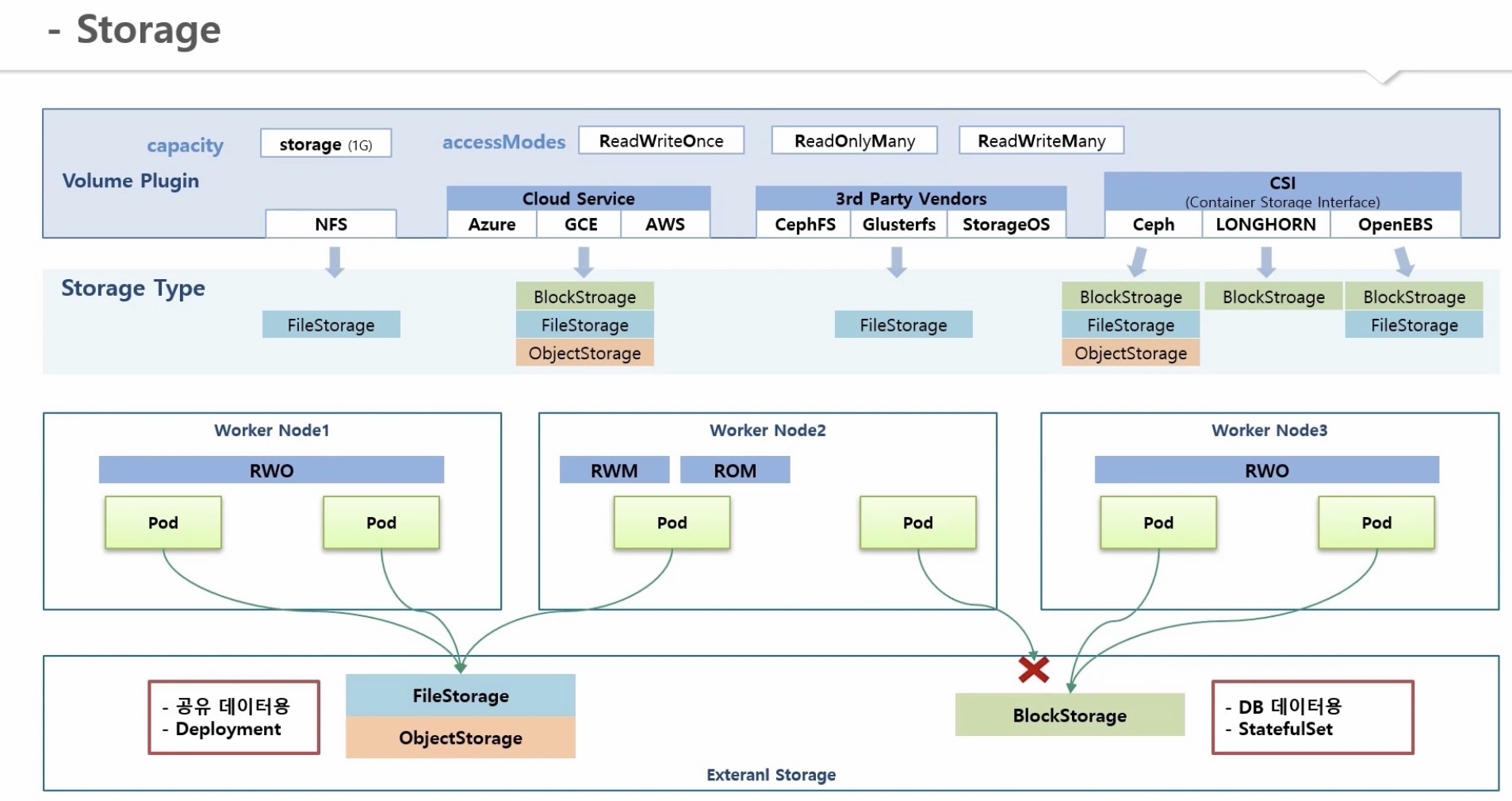
4. Storage Architecture - FileStorage(NFS), BlockStorage(Longhorn)
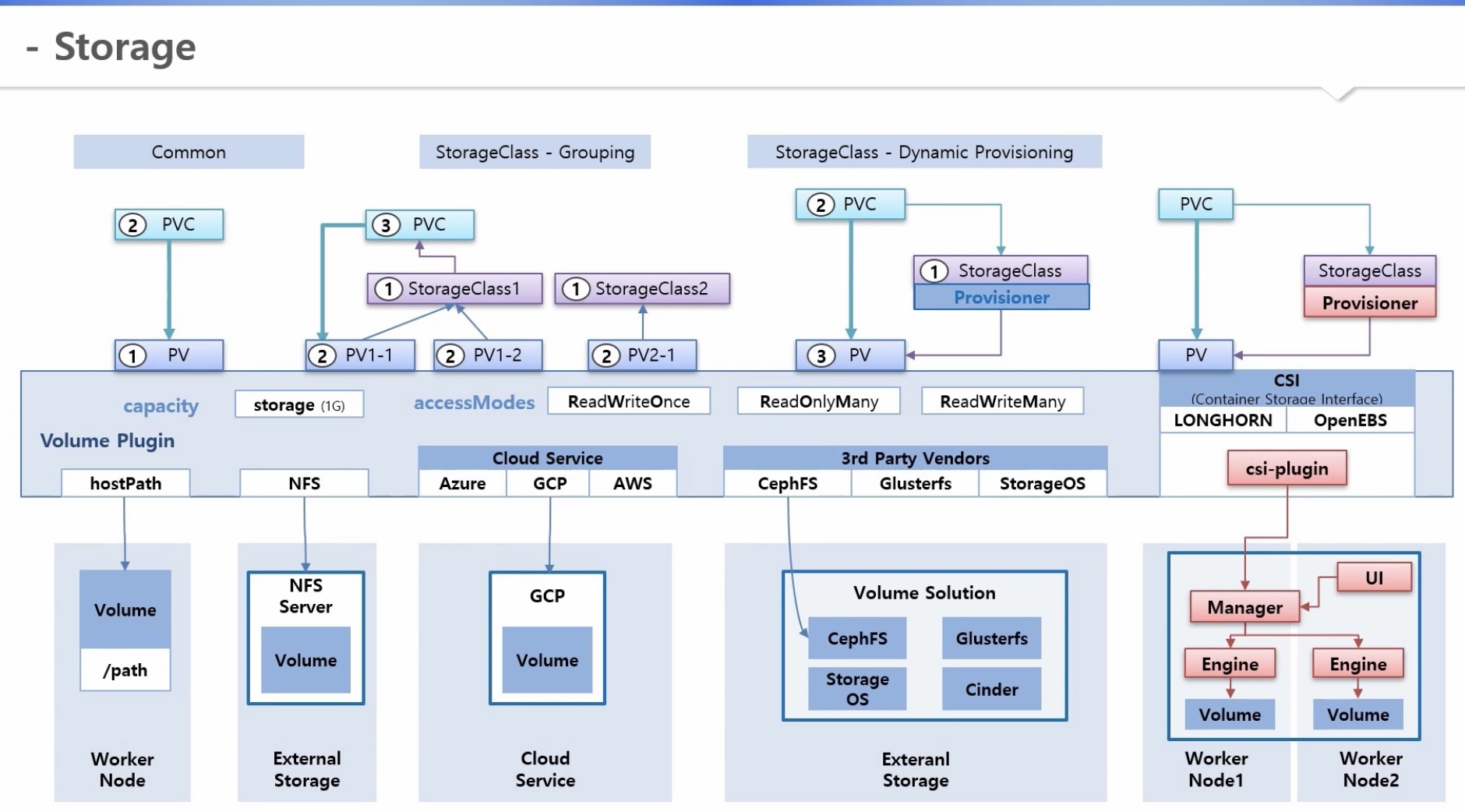
[pv 생성 방법]
1) common
a. pv 생성
b. pvc 생성 후 pv와 연결
2) storage class
a. storage class를 그룹의 개념으로 생성
b. pv 생성 시 해당 storage class 설정
c. pvc 생성 시 storage class를 지정하면 그룹 내 pv 중 알맞은 스펙의 pv와 연결
3) storage class - dynamic provisioning
a. storage class 생성 시, provisioner 지정
b. pvc 생성 시 해당 storage class 설정
c. provisioner가 pv 생성 후 pvc와 연결

[pv 상세]
1) capacity 옵션
- storage
2) accessmodes 옵션
- ReadWriteOnce, ReadOnlyMany, ReadWriteMany
3) volume plugin 옵션
a. hostPath: worker node에 지정된 패스를 pv에 대한 volume으로 지정
b. NFS: 외부 NFS 서버와 연결(NFS 클라이언트 역할, os에 설치 필수)
c. CSP(Azure, AWS, GCP 등) 서비스와 연결
d. 3rd party vendor(CephFS, StorageOS, Cinder, Glusterfs 등) 서비스와 연결
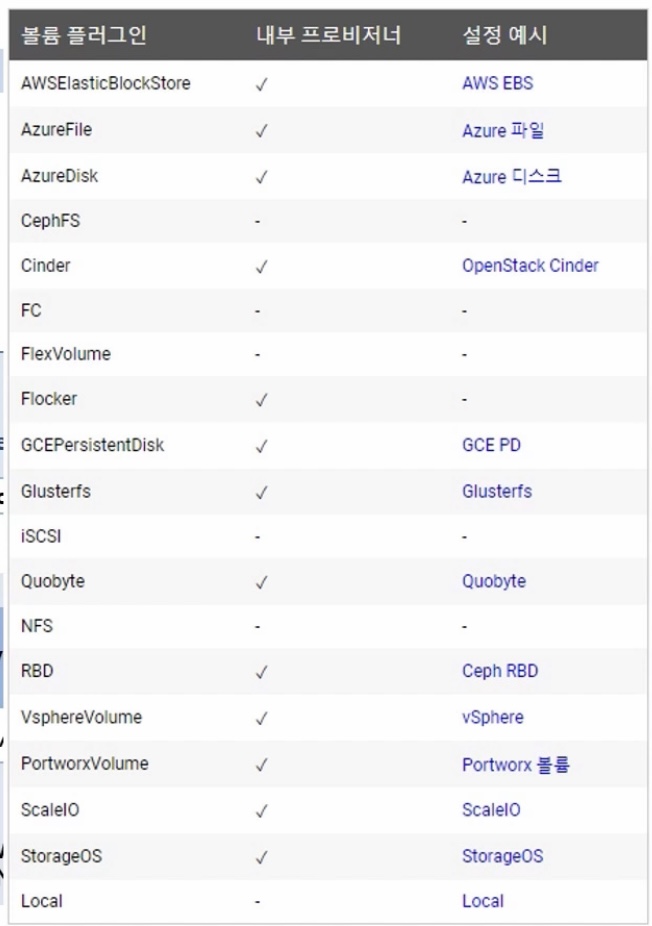
* 사용가능 plugin volum list

* plugin volum 별 dynamic provisioning 가능 여부
* CSI(Container Storge Interface)
- volume plugin 미 지정시 or 최신버전 볼륨 제어가능 plugin 필요 시
- CSI 가이드에 따라 csi-plugin 및 provisioner 생성 후 설치 방법만 사용자에게 안내
=> 사용자들은 필요 시 클러스터에 반영 가능
- 볼륨시스템 자체를 신규 컨테이너로 생성하는 기업도 있음
=> 플러그인과 볼륨솔루션을 한번에 설치함으로써 편의 증대
[pv - accessModes 상세]
* volume plugin에 따라 지원하는 storage type이 다름
1) File/Object Storage
- 여러 노드의 파드에 동시 연결 가능(RWO, RWM, ROM)
- 공유데이터용, deployment
2) BlockStorage
- 한 노드의 파드에만 연결 가능(RWO)
- db데이터용, statefulset
4. Storage Architecture - FileStorage(NFS), BlockStorage(Longhorn) 실습
[참고] https://kubetm.github.io/k8s/09-intermediate-architecture/storage/
Storage Architecture
FileStorage(NFS), BlockStorage(Longhorn)
kubetm.github.io

4. Logging(앱)/Monitoring(자원-cpu, memoy 등) Architecture
[기본]
1) Core Pipeline(default) - 파드 생성 요청 시
a. 해당 노드 kublet이 파드 생성 후 container runtime(docker 등)에게 컨테이너 생성 요청
b. 도커가 해당 노드의 디스크에 데이터를 쓰고 로그를 남기며, 컨테이너 기동 시 cpu, memory 등의 자원도 사용함
c. kublet은 해당 노드의 cAdvisor(resource estimator)를 통해 도커로 부터 cpu, memory 정보 확인 가능
d. 각 노드의 모니터링 정보는 마스터노드의 메트릭서버에 모이고, 사용자는 apiserver를 통해 kubectltop 명령어로 확인
e. 로그는 kubectllog 명령어 이용(kublet이 디스크에서 바로 조회)
2) Service Pipeline(plugin 설치)
a. daemonset을 이용한 agent 영역: cAdvisor, 도커, 워커노드로 부터 로그, 리소스 사용량 등 정보 수집
b. 별도 워커노드 구성
- 수집된 매트릭을 모으고 분석하는 서버
- 매트릭 저장소(권장)
- 웹 ui가 서버로 쿼리하여 결과 전송
c. 종류: ELK(키바나), 로키(그라파나), 프로메테우스

[Logging Architecture]
1) 노드 레벨 로깅
a. 도커 로그 생성 설정: /etc/docker/daemon.json (기본: max file 수 3개, max file size 100m => FIFO)
b. 파드 내 컨테이너에서 앱 로그 생성 => stdout/stderr 명령으로 출력된 로그만 모아 도커가 별도 로그 파일 생성
(위치: /var/lib/docker/containers/<containerID>/<containerID>-json.log)
c. k8s 로그 관리: 도커 로그 파일을 링크하여 관리(파드 삭제 시 함께 삭제)
- 1차: /var/log/pods/<namespace>_<podName>_<podID>/<containerName>/0.log
- 2차: /var/log/containers/<podName>_<containerName>_<containerID>.log
* Termination Message Path: 파드 리스타트 오류만 별도 관리 => pod detail 명령어로 확인 가능
* 파드 리스타트, 스케일 아웃 등의 상태 확인 가능
2) 클러스터 레벨 로깅
2-1) node loging agent
a. daemonset을 이용한 agent 영역 구성
b. 로깅 방법
- 노드 레벨 로그 조회: /var/log/containers/<podName>_<containerName>_<containerID>.log
- 도커 로깅 드라이브 수정: 로깅 위치를 agent로 변경
c. 로깅 데이터 수집서버로 전송
2-2) sidecar container streaming
a. 컨테이너 로그를 종류 별로 분류: ex) access log, app log
b. 별도 컨테이너를 생성하여 로그 종류 별로 stadardout 출력 => 컨테이너-로그 별 관리 가능

[Logging/Monitoring Plugin]
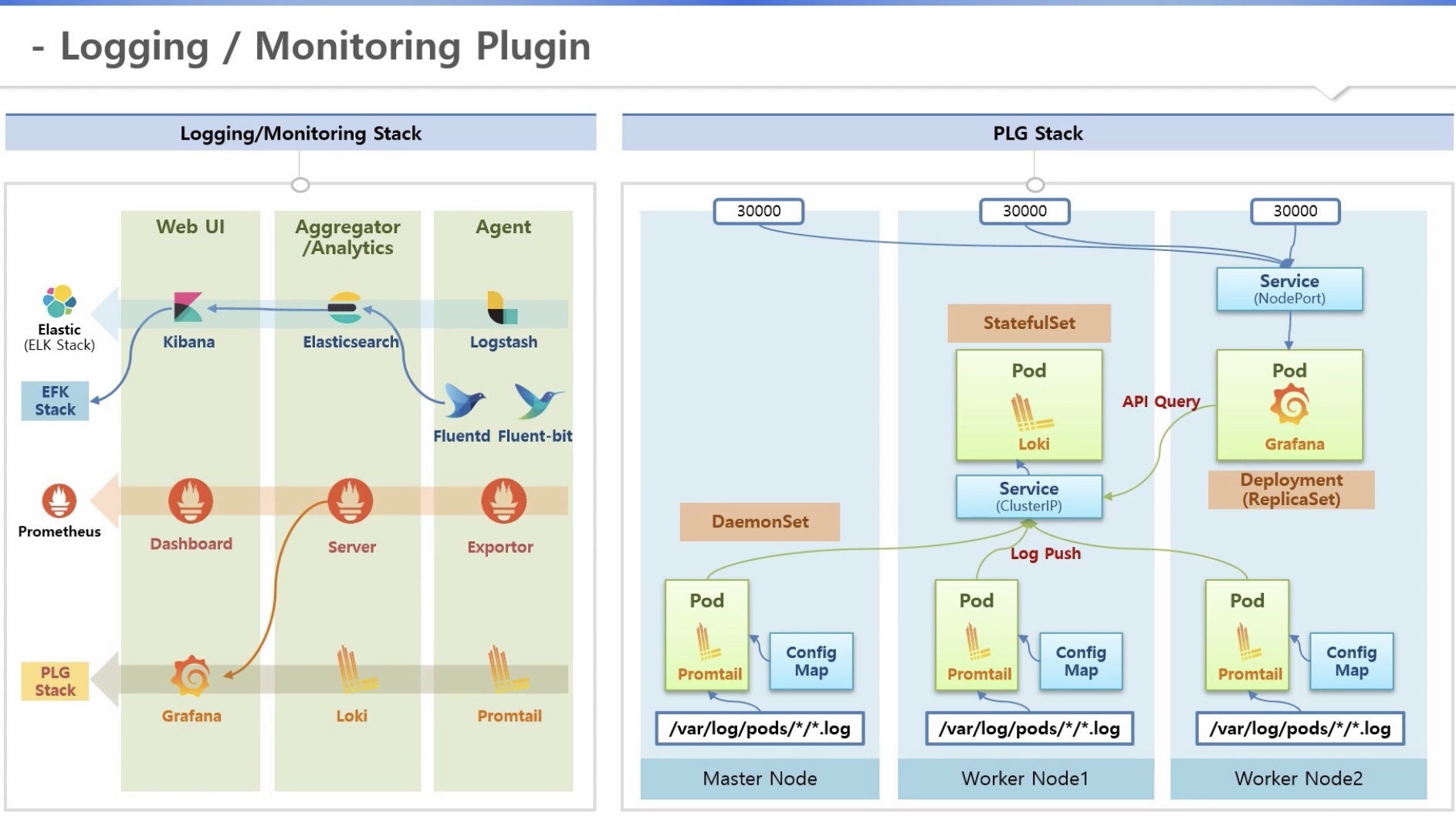
4. Logging/Monitoring Architecture 실습
[참고] https://kubetm.github.io/k8s/09-intermediate-architecture/logging/
Logging/Monitoring Architecture
Promtail, Loki, Grafana
kubetm.github.io